4.1 래딕스 정렬
프리픽스 합은 수많은 병렬 알고리즘의 중요한 기반입니다. 이 장에서는 프리픽스 합이 래딕스 정렬(radix sort)이라는 또 다른 기본적인 정렬 알고리즘을 구성하는 데 어떤 역할을 하는지 살펴보겠습니다. 이 정렬 기법은 다음 장에서 가우시안 스플래팅을 구현하는 데 중요한 역할을 할 것입니다.
래딕스 정렬의 목표는 각 키가 정수인 키-값 쌍을 키를 기준으로 정렬하는 것입니다. 이 정렬 과정은 모든 키의 한 자릿수를 한 번에 검토하는 것을 포함합니다. 예를 들어, 모든 키가 100보다 작은 십진수라면 각 키는 두 자릿수를 가집니다. 정렬하는 동안, 우리는 먼저 가장 낮은 자릿수를 고려하고 그 자릿수만을 기준으로 전체 목록을 재정렬합니다. 다음으로, 가장 높은 자릿수로 이동하여 목록을 다시 정렬합니다. 각 재정렬 단계는 안정적인 정렬이어야 한다는 점이 중요합니다. 이는 두 요소가 동일한 키를 가질 경우, 입력에서 먼저 나타난 요소가 정렬된 출력에서도 먼저 나타나야 함을 의미합니다. 이러한 안정성을 보장함으로써, 가장 낮은 자릿수를 기준으로 첫 번째 통과에서 확립된 순서를 후속 통과를 수행하는 동안 유지할 수 있습니다. 따라서 목록을 자릿수별로 정렬한 후에는 최종 목록이 키에 따라 정렬될 것이라고 확신할 수 있습니다.
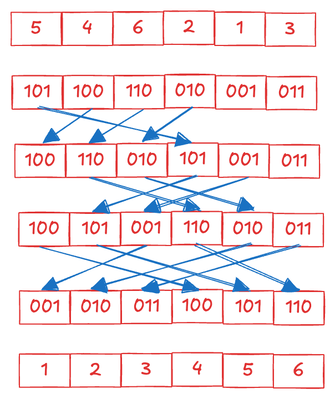
래딕스 정렬은 프리픽스 합과 어떻게 관련이 있을까요? 더 간단한 경우인 이진 키를 사용하여 이 관계를 설명해 보겠습니다. 키가 이진수이고 각 자릿수에 대해 두 가지 가능한 값(0과 1)만 있는 경우, 단일 자릿수별 정렬은 0과 1의 발생에 대한 프리픽스 합을 수행하는 것과 유사합니다. 프리픽스 합을 계산하면 각 요소가 정렬된 목록에서 차지할 새로운 위치를 예측할 수 있습니다. 예를 들어, 요소가 0이고 모든 0 발생의 프리픽스 합이 k임을 안다면, 해당 요소의 새 위치는 정렬된 목록에서 k+1이어야 합니다. 마찬가지로, 요소가 1이고 모든 1 발생의 프리픽스 합이 w임을 안다면, 해당 요소의 새 위치는 w+1+z여야 합니다. 여기서 z는 모든 0의 개수입니다.
이 접근 방식은 십진수와 같은 다른 숫자 체계의 자릿수에도 쉽게 확장될 수 있습니다. 그러나 숫자 체계를 선택할 때 고려해야 할 절충점이 있습니다. 이진수처럼 자릿수에 대한 가능한 값의 수가 적은 시스템을 사용하면 키의 자릿수가 더 많아집니다. 결과적으로 정렬 프로세스를 완료하는 데 더 많은 반복이 필요합니다. 반대로, 자릿수당 더 많은 값을 가진 시스템을 선택하면 키 길이가 짧아지지만, 각 반복에서 더 많은 프리픽스 합이 필요하고 이를 추적하기 위해 더 많은 저장 공간이 필요합니다. 이 예시에서는 4진법을 사용할 것입니다.
지금까지 설명된 것은 기본 개념입니다. 그러나 실제로는 주로 256 워크그룹 크기 제한으로 인해 추가적인 고려 사항이 있습니다. 이는 최대 512개의 배열에서만 작업할 수 있음을 의미합니다. 더 긴 목록의 경우, 목록을 여러 512 크기의 청크로 나누어야 합니다. 이를 해결하기 위해 정렬 알고리즘을 세 단계로 나눕니다.
첫 번째 단계에서는 각 청크 내에서 프리픽스 합을 계산하고 그 결과를 로컬 프리픽스 합이라고 부르는 곳에 저장합니다. 또한, 모든 가능한 자릿수 값의 총 개수를 전역 목록에 기록합니다.
두 번째 단계에서는 이 전역 목록에 대해 또 다른 프리픽스 합을 계산합니다.
마지막 단계는 셔플링 단계입니다. 여기서 로컬 프리픽스 합과 전역 자릿수 값 개수를 기반으로 결과 배열에서 각 요소의 정렬된 위치를 결정하고 해당 위치에 값을 기록합니다.
목록을 완전히 정렬하려면, 키의 자릿수 전체 길이에 대해 위에서 설명한 세 단계 프로세스를 반복해야 합니다.
@binding(0) @group(0) var input :array;
@binding(1) @group(0) var output :array>;
@binding(2) @group(0) var sums: array;
@binding(0) @group(1) var radixMaskId:u32;
const bank_size:u32 = 32;
const n:u32 = 512;
var temp0: array;
var temp1: array;
var temp2: array;
var temp3: array;
fn bank_conflict_free_idx( idx:u32) -> u32 {
var chunk_id:u32 = idx / bank_size;
return idx + chunk_id;
}
@compute @workgroup_size(256)
fn main(@builtin(global_invocation_id) GlobalInvocationID : vec3,
@builtin(local_invocation_id) LocalInvocationID: vec3,
@builtin(workgroup_id) WorkgroupID: vec3) {
var thid:u32 = LocalInvocationID.x;
var globalThid:u32 = GlobalInvocationID.x;
var mask:u32 = u32(3) << (radixMaskId << 1);
if (thid < (n>>1)){
var val:u32 = (input[2*globalThid] & mask) >> (radixMaskId << 1);
if (val == 0) {
temp0[bank_conflict_free_idx(2*thid)] = 1;
}
else if (val == 1) {
temp1[bank_conflict_free_idx(2*thid)] = 1;
}
else if (val == 2) {
temp2[bank_conflict_free_idx(2*thid)] = 1;
}
else if (val == 3) {
temp3[bank_conflict_free_idx(2*thid)] = 1;
}
val = (input[2*globalThid+1] & mask) >> (radixMaskId << 1);
if (val == 0) {
temp0[bank_conflict_free_idx(2*thid+1)] = 1;
}
else if (val == 1) {
temp1[bank_conflict_free_idx(2*thid+1)] = 1;
}
else if (val == 2) {
temp2[bank_conflict_free_idx(2*thid+1)] = 1;
}
else if (val == 3) {
temp3[bank_conflict_free_idx(2*thid+1)] = 1;
}
}
workgroupBarrier();
var offset:u32 = 1;
for (var d:u32 = n>>1; d > 0; d >>= 1)
{
if (thid < d)
{
var ai:u32 = offset*(2*thid+1)-1;
var bi:u32 = offset*(2*thid+2)-1;
temp0[bank_conflict_free_idx(bi)] += temp0[bank_conflict_free_idx(ai)];
temp1[bank_conflict_free_idx(bi)] += temp1[bank_conflict_free_idx(ai)];
temp2[bank_conflict_free_idx(bi)] += temp2[bank_conflict_free_idx(ai)];
temp3[bank_conflict_free_idx(bi)] += temp3[bank_conflict_free_idx(ai)];
}
offset *= 2;
workgroupBarrier();
}
if (thid == 0)
{
temp0[bank_conflict_free_idx(n - 1)] = 0;
temp1[bank_conflict_free_idx(n - 1)] = 0;
temp2[bank_conflict_free_idx(n - 1)] = 0;
temp3[bank_conflict_free_idx(n - 1)] = 0;
}
workgroupBarrier();
for (var d:u32 = 1; d < n; d *= 2) // traverse down tree & build scan
{
offset >>= 1;
if (thid < d)
{
var ai:u32 = offset*(2*thid+1)-1;
var bi:u32 = offset*(2*thid+2)-1;
var t:u32 = temp0[bank_conflict_free_idx(ai)];
temp0[bank_conflict_free_idx(ai)] = temp0[bank_conflict_free_idx(bi)];
temp0[bank_conflict_free_idx(bi)] += t;
t = temp1[bank_conflict_free_idx(ai)];
temp1[bank_conflict_free_idx(ai)] = temp1[bank_conflict_free_idx(bi)];
temp1[bank_conflict_free_idx(bi)] += t;
t = temp2[bank_conflict_free_idx(ai)];
temp2[bank_conflict_free_idx(ai)] = temp2[bank_conflict_free_idx(bi)];
temp2[bank_conflict_free_idx(bi)] += t;
t = temp3[bank_conflict_free_idx(ai)];
temp3[bank_conflict_free_idx(ai)] = temp3[bank_conflict_free_idx(bi)];
temp3[bank_conflict_free_idx(bi)] += t;
}
workgroupBarrier();
}
if (thid == 0) {
var count0:u32 = temp0[bank_conflict_free_idx(2*255)];
var count1:u32 = temp1[bank_conflict_free_idx(2*255)];
var count2:u32 = temp2[bank_conflict_free_idx(2*255)];
var count3:u32 = temp3[bank_conflict_free_idx(2*255)];
var last:u32 = (input[2*((WorkgroupID.x+1) * 256-1)] & mask) >> (radixMaskId << 1);
switch(last) {
case 0: {count0 += 1;}
case 1: {count1 += 1;}
case 2: {count2 += 1;}
case 3: {count3 += 1;}
default {}
}
last = (input[2*((WorkgroupID.x+1) * 256-1)+1] & mask) >> (radixMaskId << 1);
switch(last) {
case 0: {count0 += 1;}
case 1: {count1 += 1;}
case 2: {count2 += 1;}
case 3: {count3 += 1;}
default {}
}
sums[WorkgroupID.x * 4] = count0;
sums[WorkgroupID.x * 4+1] = count1;
sums[WorkgroupID.x * 4+2] = count2;
sums[WorkgroupID.x * 4+3] = count3;
}
if (thid < (n>>1)){
output[2*globalThid].x = temp0[bank_conflict_free_idx(2*thid)];
output[2*globalThid+1].x = temp0[bank_conflict_free_idx(2*thid+1)];
output[2*globalThid].y = temp1[bank_conflict_free_idx(2*thid)];
output[2*globalThid+1].y = temp1[bank_conflict_free_idx(2*thid+1)];
output[2*globalThid].z = temp2[bank_conflict_free_idx(2*thid)];
output[2*globalThid+1].z = temp2[bank_conflict_free_idx(2*thid+1)];
output[2*globalThid].w = temp3[bank_conflict_free_idx(2*thid)];
output[2*globalThid+1].w = temp3[bank_conflict_free_idx(2*thid+1)];
}
}
위 코드는 이전 장에서 설명한 프리픽스 합 알고리즘을 수정한 것입니다. 여기서는 수정 사항에 중점을 두고 설명하겠습니다. 먼저 입력과 출력부터 살펴보겠습니다:
@binding(0) @group(0) var input :array;
@binding(1) @group(0) var output :array>;
@binding(2) @group(0) var sums: array;
입력 배열은 동일하지만, 출력은 이제 vec4 벡터를 저장합니다. 4진법을 사용하므로 벡터는 0, 1, 2, 3 자릿수에 대한 합계를 저장합니다. 또한, 각 청크 내의 모든 자릿수의 총 개수를 추적하기 위한 합계 배열(sums array)이 있습니다.
@binding(0) @group(1) var radixMaskId:u32;
다음으로, 현재 포커스해야 할 자릿수를 나타내는 radixMaskId를 정의합니다. 키가 uint32 형식이고 4진법을 사용하므로, 16개의 가능한 자릿수가 있습니다. 따라서 radixMaskId의 값은 0부터 15까지입니다. radixMaskId를 사용하여 다음 공식을 통해 마스크를 계산할 수 있습니다:
var mask:u32 = u32(3) << (radixMaskId << 1);
다음으로, 계산을 위한 임시 배열을 정의합니다:
const n:u32 = 512;
var temp0: array;
var temp1: array;
var temp2: array;
var temp3: array;
다음 단계는 값을 임시 배열에 로드하는 것입니다. 현재 관심 있는 자릿수를 추출하고, 자릿수의 값에 따라 임시 배열의 해당 위치를 1로 설정하여 한 번의 발생을 나타냅니다.
var thid:u32 = LocalInvocationID.x;
var globalThid:u32 = GlobalInvocationID.x;
var mask:u32 = u32(3) << (radixMaskId << 1);
if (thid < (n>>1)){
var val:u32 = (input[2*globalThid] & mask) >> (radixMaskId << 1);
if (val == 0) {
temp0[bank_conflict_free_idx(2*thid)] = 1;
}
else if (val == 1) {
temp1[bank_conflict_free_idx(2*thid)] = 1;
}
else if (val == 2) {
temp2[bank_conflict_free_idx(2*thid)] = 1;
}
else if (val == 3) {
temp3[bank_conflict_free_idx(2*thid)] = 1;
}
val = (input[2*globalThid+1] & mask) >> (radixMaskId << 1);
if (val == 0) {
temp0[bank_conflict_free_idx(2*thid+1)] = 1;
}
else if (val == 1) {
temp1[bank_conflict_free_idx(2*thid+1)] = 1;
}
else if (val == 2) {
temp2[bank_conflict_free_idx(2*thid+1)] = 1;
}
else if (val == 3) {
temp3[bank_conflict_free_idx(2*thid+1)] = 1;
}
}
workgroupBarrier();
다음 로직은 프리픽스 합 프로그램과 유사하며, 주요 차이점은 네 개의 임시 배열에서 수행된다는 것입니다. 프리픽스 합이 계산되면, 이 청크에서 자릿수의 전체 개수를 얻어야 합니다. 우리의 프리픽스 합은 마지막 값을 포함하지 않으므로, 프리픽스 합 배열의 마지막 요소를 검색하고, 마지막 입력 요소를 세어 그 결과를 합계 배열에 저장해야 합니다. 각 워크그룹은 이러한 값의 한 세트만 생성하므로, 이 워크그룹의 첫 번째 스레드만 저장 작업을 수행하도록 요청합니다.
if (thid == 0) {
var count0:u32 = temp0[bank_conflict_free_idx(2*255)];
var count1:u32 = temp1[bank_conflict_free_idx(2*255)];
var count2:u32 = temp2[bank_conflict_free_idx(2*255)];
var count3:u32 = temp3[bank_conflict_free_idx(2*255)];
var last:u32 = (input[2*((WorkgroupID.x+1) * 256-1)] & mask) >> (radixMaskId << 1);
switch(last) {
case 0: {count0 += 1;}
case 1: {count1 += 1;}
case 2: {count2 += 1;}
case 3: {count3 += 1;}
default {}
}
last = (input[2*((WorkgroupID.x+1) * 256-1)+1] & mask) >> (radixMaskId << 1);
switch(last) {
case 0: {count0 += 1;}
case 1: {count1 += 1;}
case 2: {count2 += 1;}
case 3: {count3 += 1;}
default {}
}
sums[WorkgroupID.x * 4] = count0;
sums[WorkgroupID.x * 4+1] = count1;
sums[WorkgroupID.x * 4+2] = count2;
sums[WorkgroupID.x * 4+3] = count3;
}
두 번째 통과에서는 또 다른 프리픽스 합을 수행합니다. 이전 통과에서 생성된 합계 배열을 가져와서 프리픽스 합을 계산합니다. 이 통과는 표준 접근 방식을 따르므로 자세한 설명은 생략하겠습니다. 단순화를 위해 청크 수가 512 미만이라고 가정하여 단일 워크그룹으로 두 번째 통과를 수행할 수 있습니다. 이는 우리가 처리할 수 있는 최대 배열 크기를 512x512로 본질적으로 제한합니다.
세 번째 통과는 셔플링 통과입니다. 이 통과에서는 정렬된 배열에서 각 요소의 위치를 계산하고 해당 자릿수 값을 결과 배열에 할당합니다.
@binding(0) @group(0) var input :array;
@binding(1) @group(0) var inputId :array;
@binding(2) @group(0) var temp :array>;
@binding(3) @group(0) var sums: array;
@binding(4) @group(0) var sumSize: u32;
@binding(5) @group(0) var output :array;
@binding(6) @group(0) var outputId :array;
const n:u32 = 512;
@binding(0) @group(1) var radixMaskId:u32;
@compute @workgroup_size(256)
fn main(@builtin(global_invocation_id) GlobalInvocationID : vec3,
@builtin(local_invocation_id) LocalInvocationID: vec3,
@builtin(workgroup_id) WorkgroupID: vec3) {
var thid:u32 = LocalInvocationID.x;
var globalThid:u32 = GlobalInvocationID.x;
var mask:u32 = u32(3) << (radixMaskId << 1);
var count0beforeCurrentWorkgroup:u32 = 0;
var count1beforeCurrentWorkgroup:u32 = 0;
var count2beforeCurrentWorkgroup:u32 = 0;
var count3beforeCurrentWorkgroup:u32 = 0;
if (WorkgroupID.x > 0) {
count0beforeCurrentWorkgroup = sums[(WorkgroupID.x-1) * 4];
count1beforeCurrentWorkgroup = sums[(WorkgroupID.x-1) * 4+1];
count2beforeCurrentWorkgroup = sums[(WorkgroupID.x-1) * 4+2];
count3beforeCurrentWorkgroup = sums[(WorkgroupID.x-1) * 4+3];
}
var count0overall:u32 = sums[(sumSize-1)*4];
var count1overall:u32 = sums[(sumSize-1)*4+1];
var count2overall:u32 = sums[(sumSize-1)*4+2];
var count3overall:u32 = sums[(sumSize-1)*4+3];
if (thid < (n>>1)){
var val:u32 = (input[2*globalThid] & mask) >> (radixMaskId << 1);
var id:u32 = 0;
if (val == 0) {
id += temp[2*globalThid].x + count0beforeCurrentWorkgroup;
}
else if (val == 1) {
id +=count0overall;
id += temp[2*globalThid].y + count1beforeCurrentWorkgroup;
}
else if (val == 2) {
id += count0overall;
id += count1overall;
id += temp[2*globalThid].z + count2beforeCurrentWorkgroup;
}
else if (val == 3) {
id +=count0overall;
id +=count1overall;
id +=count2overall;
id += temp[2*globalThid].w +count3beforeCurrentWorkgroup;
}
output[id] = input[2*globalThid];
outputId[id] = inputId[2*globalThid];
//output[2*globalThid] = id;
id = 0;
val = (input[2*globalThid+1] & mask) >> (radixMaskId << 1);
if (val == 0) {
id += temp[2*globalThid+1].x + count0beforeCurrentWorkgroup;
}
else if (val == 1) {
id +=count0overall;
id += temp[2*globalThid+1].y + count1beforeCurrentWorkgroup;
}
else if (val == 2) {
id += count0overall;
id += count1overall;
id += temp[2*globalThid+1].z + count2beforeCurrentWorkgroup;
}
else if (val == 3) {
id +=count0overall;
id +=count1overall;
id +=count2overall;
id += temp[2*globalThid+1].w+ count3beforeCurrentWorkgroup ;
}
output[id] = input[2*globalThid+1];
outputId[id] = inputId[2*globalThid+1];
//output[2*globalThid+1] = id;
}
}
이제 JavaScript 쪽을 살펴보며 입력 데이터 설정 및 컴퓨트 셰이더 트리거 방법을 알아보겠습니다.
let testArray = [];
let testIdArray = [];
{
//load data
const objResponse = await fetch('../data/dummy.json');
testArray = await objResponse.json();
}
const actualArraySize = testArray.length; // 81946;//512*2+10;
const paddedArraySize = Math.ceil(actualArraySize / 512) * 512;
const chunkCount = Math.ceil(paddedArraySize / 512);
let sumSize = roundUpToNearestPowOf2(chunkCount);
console.log("pos", Number.POSITIVE_INFINITY)
for (let i = 0; i < paddedArraySize; ++i) {
if (i < actualArraySize) {
// testArray.push(Math.floor(random() * 0xFFFFFFFE));
} else {
testArray.push(0xFFFFFFFF);
}
testIdArray.push(i);
}
testArray는 우리의 입력 배열입니다. 무작위 배열을 생성하는 대신, 입력 데이터는 이전 장의 샘플을 디버깅하는 동안 생성된 파일에서 읽어옵니다. 이 배열은 무작위 배열로 생각할 수 있습니다. 두 가지 배열 크기가 있습니다: 실제 입력 배열의 크기인 actualArraySize와 512의 가장 가까운 배수로 반올림된 배열 크기인 paddedArraySize입니다. 이는 단일 워크그룹이 512개의 요소를 정렬할 수 있기 때문입니다.
또한 워크그룹 또는 청크의 수를 나타내는 chunkCount 변수가 있습니다. 앞서 언급했듯이, 각 청크의 자릿수 개수는 두 번째 프리픽스 합 통과에서 누적됩니다. sumSize는 이진 트리 구조를 사용하여 병렬 프리픽스 합을 계산하는 데 필요한 가장 가까운 2의 거듭제곱으로 반올림됩니다.
패딩된 값의 경우, 정렬된 배열의 끝에 나타나도록 큰 숫자 0xFFFFFFFF를 할당합니다. 다음 단계는 입력 및 출력 배열을 담을 일련의 GPU 버퍼를 설정하는 것이며, 이는 간단하므로 생략하겠습니다.
래딕스 마스크도 설정해야 합니다:
let radixIdUniformBuffers = [];
for (let i = 0; i < 16; ++i) {
let radixIdUniformBuffer = createGPUBuffer(device, new Uint32Array([i]), GPUBufferUsage.UNIFORM);
radixIdUniformBuffers.push(radixIdUniformBuffer);
}
4진법을 사용하므로, 매번 두 개의 이진 자릿수를 살펴봅니다. 우리의 마스크는 0b11이며, 래딕스의 위치에 따라 왼쪽으로 시프트됩니다. 마스크를 직접 인코딩하는 대신 마스크의 위치를 인코딩합니다. 부호 없는 32비트 정수의 경우 16개의 자릿수 위치가 있습니다. 따라서 radixId를 0부터 15까지의 범위로 설정합니다. 이 위치를 별도의 GPU 버퍼에 인코딩하여 계산 중에 해당 유니폼 버퍼를 로드하여 radixId를 쉽게 지정할 수 있습니다.
마지막으로, 세 가지 통과가 어떻게 트리거되는지 살펴보겠습니다:
const commandEncoder = device.createCommandEncoder();
if (hasTimestampQuery) {
commandEncoder.writeTimestamp(querySet, 0);// Initial timestamp
}
for (let i = 0; i < 16; ++i) {
const passEncoder = commandEncoder.beginComputePass(
computePassDescriptor
);
passEncoder.setPipeline(pass1ComputePipeline);
if (i % 2 == 0) {
passEncoder.setBindGroup(0, pass1UniformBindGroupInputOutput0);
}
else {
passEncoder.setBindGroup(0, pass1UniformBindGroupInputOutput1);
}
passEncoder.setBindGroup(1, pass13UniformBindGroupRadixIds[i]);
passEncoder.dispatchWorkgroups(chunkCount);
passEncoder.end();
const pass2Encoder = commandEncoder.beginComputePass(computePassDescriptor);
pass2Encoder.setPipeline(pass2ComputePipeline);
pass2Encoder.setBindGroup(0, pass2UniformBindGroup);
pass2Encoder.dispatchWorkgroups(1);
pass2Encoder.end();
const pass3Encoder = commandEncoder.beginComputePass(computePassDescriptor);
pass3Encoder.setPipeline(pass3ComputePipeline);
if (i % 2 == 0) {
pass3Encoder.setBindGroup(0, pass3UniformBindGroup0);
} else {
pass3Encoder.setBindGroup(0, pass3UniformBindGroup1);
}
pass3Encoder.setBindGroup(1, pass13UniformBindGroupRadixIds[i]);
pass3Encoder.dispatchWorkgroups(chunkCount);
pass3Encoder.end();
}
16개의 래딕스 위치가 있으므로 16번 반복합니다. 각 반복은 세 번의 통과를 수행합니다. 첫 번째 및 세 번째 통과에서는 효율성을 높이고 불필요한 데이터 복사를 피하기 위해 입력 및 출력 배열의 역할을 번갈아 가며 사용합니다. 마지막으로, 정렬된 배열을 다시 읽어오지만 자세한 내용은 생략하겠습니다.