5.5 깊이 필링을 활용한 투명도
투명도는 3D 그래픽스 API에서 기본적으로 지원하지 않는 또 다른 중요한 시각 효과이며, 그 구현은 간단하지 않습니다. 이전에 알파 블렌딩을 소개하고 텍스트 렌더링과 같은 반투명 효과를 달성하는 데 사용했습니다. 그러나 3D 객체의 경우 알파 블렌딩만으로는 올바른 결과를 얻을 수 없습니다.
플레이그라운드 실행 - 5_05_transparency근본적인 문제는 깊이 테스트가 가려짐을 구현하는 데 필요하지만 투명도 렌더링과 충돌한다는 것입니다. 불투명한 객체와 투명한 객체가 모두 있는 3D 장면을 상상해 보세요. 깊이 테스트를 비활성화하면 가려짐이 제대로 렌더링되지 않습니다. 그러나 깊이 테스트를 활성화하면 불투명한 객체 앞에 있는 투명한 객체가 불투명한 객체를 가릴 것입니다. 올바른 렌더링은 투명한 객체가 불투명한 객체 위에 놓여 투명한 객체를 통해 뒤에 있는 불투명한 객체를 볼 수 있도록 해야 합니다.
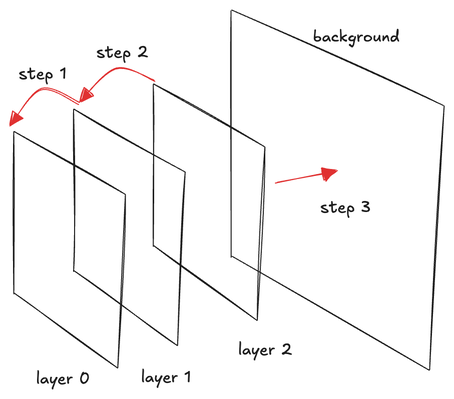
한 가지 단순한 아이디어는 장면의 객체를 뒤에서 앞으로 순서대로 그리는 것이며, 깊이 테스트는 각 개별 객체에만 적용하고, 다른 객체 위에 겹쳐 놓을 때는 끄는 것입니다. 이전에 포토샵을 사용해 본 적이 있다면, 이것은 레이어의 개념과 유사합니다. 문제는 특정 상황에서 객체의 순서를 정하기 어렵다는 것입니다. 예를 들어:

객체 순서 지정이 좋은 해결책이 아니라면, 삼각형 순서 지정을 고려할 수 있습니다. 그러나 객체 순서 지정과 마찬가지로, 삼각형의 순서를 결정하는 것은 어려울 수 있습니다. 예를 들어:

이 튜토리얼에서는 깊이 필링이라는 더 나은 기술을 살펴보겠습니다. 이 아이디어는 포토샵의 레이어와 유사하지만, 객체나 삼각형을 레이어로 취급하는 대신 장면을 앞에서 뒤로 벗겨내어 각 벗겨낸 장면을 레이어로 배치하고 함께 합성하여 최종 렌더링을 형성합니다.
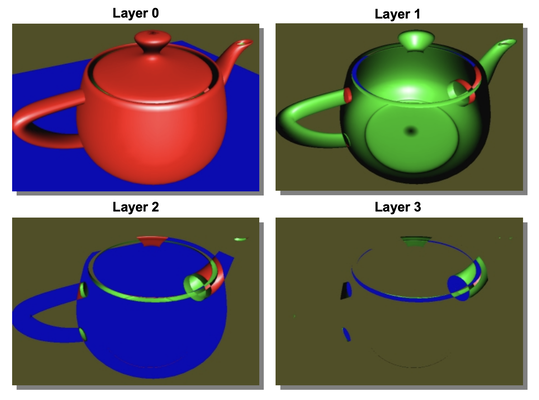
장면을 벗겨낸다는 것이 무엇을 의미하는지 설명하겠습니다. 먼저 깊이 테스트로 장면을 렌더링합니다. 이렇게 하면 투명도와 관계없이 가장 앞에 있는 객체가 렌더링됩니다. 동시에 깊이 맵을 유지합니다. 렌더링 결과는 레이어 0이 됩니다. 그런 다음 장면을 다시 렌더링하지만, 첫 번째 깊이 맵 뒤에 있는 프래그먼트, 즉 초기 깊이 값보다 깊이가 더 큰 프래그먼트만 렌더링합니다. 결과적으로 가장 앞에 있는 프래그먼트를 벗겨내고 두 번째 레이어의 프래그먼트인 레이어 1이 드러납니다. 마찬가지로 이 새로운 깊이 맵을 유지합니다. 이제부터 이 절차를 반복하여 장면을 다시 렌더링하고 깊이 값이 현재 깊이 맵보다 큰 경우에만 프래그먼트를 유지합니다. 이것이 레이어 2 등이 됩니다.
결론적으로, 우리는 깊이에 따라 장면을 일련의 레이어로 분해할 것입니다. 최종 패스에서는 알파 블렌딩을 사용하여 앞에서 뒤로 레이어를 합성하여 최종 결과를 만듭니다.
깊이 필링의 핵심 개념은 어렵지 않습니다. 이를 철저히 이해하는 데 있어 중요한 측면 중 하나는 앞에서 뒤로 블렌딩에 사용되는 알파 블렌딩 공식을 파악하는 것입니다.
저는 수년 동안 컴퓨터 그래픽스 분야에서 일했지만, 알파 블렌딩과 미리 곱해진 알파, 뒤에서 앞으로 블렌딩, 앞에서 뒤로 블렌딩과 같은 개념들이 혼란스러웠다는 것을 인정해야 합니다. 다양한 상황에 대한 공식을 온라인에서 쉽게 찾을 수 있지만, 그 밑에 깔린 원리를 진정으로 이해하는 것이 더 복잡한 경우를 다루는 데 중요합니다.
저는 Advanced Graphics Programming Using OpenGL 책에 감사함을 표하고 싶습니다. 이 책에는 알파 블렌딩이 어떻게 작동하는지 (185페이지부터) 인내심 있게 설명하는 전용 챕터가 있습니다.
저의 초반 혼란은 알파를 실제 생활에서 투명도를 인식하는 방식과 유사하게 불투명도로 개념화했기 때문입니다. 예를 들어, 반투명한 빨간색 필름을 상상해 보면, 빨간색은 색상이고 알파는 반투명도를 나타냅니다. 이러한 오해로 인해 저는 미리 곱해진 알파와 같은 개념을 이해하기 어려웠습니다. 실제 생활에서 객체의 색상은 일반적으로 투명도와 관련이 없습니다. 매우 투명한 빨간색 필름도 여전히 빨간색으로 보여야 합니다. 그러나 컴퓨터 그래픽스에서는 미리 곱해진 알파라는 개념이 있는데, 여기서는 알파 값을 색상과 곱하여 매우 투명한 빨간색이 어두운 빨간색 또는 심지어 검은색으로 보이게 합니다.
알파를 개념화하는 올바른 방법은 불투명도가 아니라 "색상의 양"입니다. 컴퓨터 그래픽스에는 진정한 투명도라는 것은 없으며, 모든 안료가 완전히 불투명하고 색상만 다른 그림과 더 유사합니다.
반투명의 환상을 만들기 위해, 우리는 기존 색상의 가중 평균을 취하여 색상을 혼합해야 하며, 이는 여러 색상 레이어를 통과하는 빛의 효과를 시뮬레이션합니다. 색상을 혼합할 때 유일하게 제어할 수 있는 요소는 색상의 양이며, 이는 RGBA 픽셀의 알파 채널에 해당합니다.
따라서 두 색상 간의 알파 블렌딩의 가장 기본적인 형태는 다음과 같습니다:
\begin{aligned}
C_{new} &= C_{src} * A_{src} + C_{dst} * (1 - A_{src}) \\
A_{new} &= 1.0
\end{aligned}
이것은 두 색상의 일반적인 가중 평균을 설명하며, 두 색상과 결과 색상 C_{new}는 완전히 불투명하다고 가정합니다. 이 경우 C_{src}만 알파 값을 가지며 공식에 사용되는 반면, C_{dst}와 C_{new}는 알파 값이 1.0(완전 불투명)입니다. 만약 C_{src}가 전경 색상이라면, 이 공식은 실제 투명도 없이 전경 색상이 얼마나 보일지를 결정합니다.
각 픽셀을 작은 색상 버킷으로 생각할 수 있으며, 단일 버킷에 부을 수 있는 색상의 양은 1.0을 초과할 수 없습니다(즉, 오버플로 없음).
두 색상을 혼합할 때, 모든 픽셀 버킷이 처음에는 배경 색상 C_{dst}로 완전히 불투명하게(1.0) 채워져 있다고 상상할 수 있습니다. 알파 값 A_{src}를 가진 전경 색상을 추가할 공간을 만들기 위해, 기존 색상 중 일부를 제거해야 합니다. 결과 버킷이 가득 찬 상태를 유지하려면 제거할 양은 1.0−A_{src}여야 합니다.
두 개 이상의 색상을 추가적으로 혼합할 때, 우리는 각 단계에서 결과 색상이 알파를 가지지 않는다고 가정할 수 없으므로 공식을 조정해야 합니다(즉, 항상 가득 찬 버킷이 아님).
이 버킷에 색상을 추가할 때, 이미 존재하는 색상의 양을 고려해야 합니다. 이것이 버킷에 있는 현재 색상 양을 추적해야 하는 이유입니다.
블렌딩할 색상을 C_1, C_2, C_3 등으로 레이블링하겠습니다. 여러 색상을 블렌딩하기 위한 공식은 다음과 같습니다:
\begin{aligned}
C_{new} &= C_1 * A_1 + C_2 * A_2 * (1.0 - A_1) \\
A_{new} &= A_1 + A_2 * (1.0 - A_1)
\end{aligned}
두 색상의 가중 평균은 동일하게 유지되지만, 이제 C_2는 알파 A_2로 곱해지는데, 이는 C_2가 완전히 불투명하지 않기 때문입니다.
새로운 알파 공식인 A_{new} = A_1 + A_2 * (1.0−A_1)는 새로운 알파가 1.0을 초과하지 않도록 보장하여 오버플로를 방지합니다.
언뜻 보기에 온라인에서 흔히 볼 수 있는 앞에서 뒤로 알파 블렌딩에 대한 일반적인 방정식은 위의 공식과 일치하지 않는 것처럼 보일 수 있습니다. 그러나 실제로는 동일합니다. 앞에서 뒤로 알파 블렌딩에서는 대상 색상이 전경이고 원본이 배경입니다. 다음 공식은 위의 방정식에서 (1.0−A_1) 항을 저장하기 위해 A_{dst}를 사용합니다. C_{src}와 A_{src}를 C_2와 A_2로, C_{dst}와 A_{dst}를 C_1과 (1.0−A_1)으로 대체하면 동일한 방정식을 얻습니다:
\begin{aligned}
C_{dst} &= A_{dst} * (A_{src} * C_{src}) + C_{dst} \\
A_{dst} &= (1 - A_{src}) * A_{dst}
\end{aligned}
이제 블렌딩 방정식을 명확히 했으니, 구현을 살펴보겠습니다:
@group(0) @binding(0)
var modelView: mat4x4;
@group(0) @binding(1)
var projection: mat4x4;
@group(0) @binding(2)
var normalMatrix: mat4x4;
@group(0) @binding(3)
var lightDirection: vec3;
@group(0) @binding(4)
var viewDirection: vec3;
@group(1) @binding(0)
var offset: vec3;
@group(1) @binding(1)
var ambientColor:vec4;// = vec4(0.15, 0.10, 0.10, 1.0);
@group(1) @binding(2)
var diffuseColor:vec4;// = vec4(0.55, 0.55, 0.55, 1.0);
@group(1) @binding(3)
var specularColor:vec4;// = vec4(1.0, 1.0, 1.0, 1.0);
@group(1) @binding(4)
var shininess:f32;// = 20.0;
const diffuseConstant:f32 = 1.0;
const specularConstant:f32 = 1.0;
const ambientConstant: f32 = 1.0;
fn specular(lightDir:vec3, viewDir:vec3, normal:vec3, specularColor:vec3,
shininess:f32) -> vec3 {
let reflectDir:vec3 = reflect(-lightDir, normal);
let specDot:f32 = max(dot(reflectDir, viewDir), 0.0);
return pow(specDot, shininess) * specularColor;
}
fn diffuse(lightDir:vec3, normal:vec3, diffuseColor:vec3) -> vec3{
return max(dot(lightDir, normal), 0.0) * diffuseColor;
}
struct VertexOutput {
@builtin(position) clip_position: vec4,
@location(0) viewDir: vec3,
@location(1) normal: vec3,
@location(2) lightDir: vec3,
@location(3) inPos: vec4,
};
@vertex
fn vs_main(
@location(0) inPos: vec3,
@location(1) inNormal: vec3
) -> VertexOutput {
var out: VertexOutput;
out.viewDir = normalize((normalMatrix * vec4(-viewDirection, 0.0)).xyz);
out.lightDir = normalize((normalMatrix * vec4(-lightDirection, 0.0)).xyz);
out.normal = normalize(normalMatrix * vec4(inNormal, 0.0)).xyz;
var wldLoc:vec4 = modelView * vec4(inPos+offset, 1.0);
out.clip_position = projection * wldLoc;
out.inPos = projection * wldLoc;
return out;
}
@group(2) @binding(0)
var t_depth: texture_depth_2d;
@group(2) @binding(1)
var s_depth: sampler_comparison;
@group(2)
@binding(2)
var debug: vec4;
@fragment
fn fs_main(in: VertexOutput, @builtin(front_facing) face: bool) -> @location(0) vec4 {
var uv:vec2 = 0.5*(in.inPos.xy/in.inPos.w + vec2(1.0,1.0));
var visibility:f32 = textureSampleCompare(
t_depth, s_depth,
vec2(uv.x, 1.0-uv.y), in.clip_position.z - 0.0001
);
debug = in.clip_position;
//debug = in.inPos;
//debug = vec4(uv,in.inPos.z/in.inPos.w, in.clip_position.z);
if (visibility < 0.5) {
discard;
}
var lightDir:vec3 = normalize(in.lightDir);
var n:vec3 = normalize(in.normal);
var color:vec3 = diffuseColor.rgb;
if (!face) {
n = normalize(-in.lightDir);
// color = vec3(0.0, 1.0, 0.0);
}
var viewDir: vec3 = in.viewDir;
var radiance:vec3 = ambientColor.rgb * ambientConstant +
diffuse(-lightDir, n, color)* diffuseConstant +
specular(-lightDir, viewDir, n, specularColor.rgb, shininess) * specularConstant;
//return vec4(uv.xy,0.0,1.0);
return vec4(radiance * diffuseColor.w, diffuseColor.w);
}
이 셰이더는 친숙하게 보일 것입니다. 조명 셰이더와 비슷하지만 약간의 수정이 있습니다. 이 셰이더는 깊이 맵을 로드하고 현재 깊이 값을 깊이 맵의 값과 비교합니다. 새 깊이가 맵의 깊이보다 클 때만 프래그먼트를 렌더링하는데, 이는 깊이 맵 이전에 있는 객체를 벗겨낼 수 있도록 합니다.
out.clip_position = projection * wldLoc;
out.inPos = projection * wldLoc;
var uv:vec2 = 0.5*(in.inPos.xy/in.inPos.w + vec2(1.0,1.0));
var visibility:f32 = textureSampleCompare(
t_depth, s_depth,
vec2(uv.x, 1.0-uv.y), in.clip_position.z - 0.0001
);
debug = in.clip_position;
//debug = in.inPos;
//debug = vec4(uv,in.inPos.z/in.inPos.w, in.clip_position.z);
깊이 맵 페칭을 위한 UV 좌표 계산 로직과 현재 깊이에 주목할 필요가 있습니다. `clip_position`과 `inPos`라는 두 변수가 모두 클립 공간 위치 벡터를 저장하는 것처럼 보이는 것이 특이하다고 생각할 수 있습니다. 이것들은 중복되어 보입니다.
이는 의도적인 것으로, 정점 셰이더 단계에서 프래그먼트 셰이더에 전달되는 `clip_position` 변수가 변경된다는 것을 보여주기 위함입니다. 따라서 프래그먼트 셰이더에서 다시 읽을 때, 변수 이름이 같더라도 동일한 클립 위치가 아닙니다.
GPU 파이프라인을 소개했을 때, 정점 셰이더 단계에서는 각 정점에 대해 속성을 희소하게만 정의한다는 것을 배웠습니다. 그런 다음 래스터화라는 단계에서 삼각형 지오메트리를 프래그먼트로 변환하는데, 이는 벽돌을 놓는 것과 유사합니다. 각 프래그먼트에서 정의된 값은 이중선형 보간을 통해 얻어집니다. 보간이 일부 값 변경을 설명하지만, 모든 변경을 설명하지는 않습니다. 또 다른 중요한 변경은 파이프라인이 좌표계를 변경한다는 것입니다. x와 y의 경우, 파이프라인은 클립 공간에서 정규화된 장치 좌표로 변환하고, 그런 다음 정규화된 장치 좌표에서 프레임버퍼 좌표로 변환합니다(여기서 왼쪽 상단 모서리는 (0.0, 0.0)이고, x는 오른쪽으로 증가하고 y는 아래쪽으로 증가합니다). z의 경우, 뷰포트 깊이 범위 내의 값으로 매핑됩니다: vp.minDepth+n.z×(vp.maxDepth−vp.minDepth).
프래그먼트 셰이더로 전달되는 값을 설명하는 기술 용어가 있습니다: RasterizationPoint. 변수 이름이 같더라도 데이터에 변경이 있다는 점을 명심하십시오.
이를 염두에 두면 UV 계산을 이해하는 것은 간단할 것입니다. 우리는 정규화된 장치 좌표(NDC) 범위를 [-1,1]에서 [0,1]로 매핑하고, 텍스처 좌표가 아래로 증가하므로 y축을 뒤집습니다. z 값의 경우, 단순히 clip_position.z에서 읽습니다.
이 파이프라인을 설정하는 방법을 살펴보겠습니다.
먼저, 배경 역할을 할 빈 캔버스가 필요합니다. 우리는 앞에서 뒤로 렌더링하고 최종적으로 렌더링된 것을 배경 위에 겹쳐 놓습니다.
각 라운드 시작 시, 대상(dst) 텍스처를 (0, 0, 0, 1)로 지워야 합니다. 이는 아무것도 그릴 필요 없이 색상 첨부 파일을 지우는 내장 기능을 사용하여 쉽게 달성할 수 있습니다. dst 텍스처는 앞에서 뒤로 알파 블렌딩을 위한 레이어 0 역할을 합니다. 첫 번째 레이어는 이 텍스처와 블렌딩되고, 두 번째 레이어는 결과 텍스처와 블렌딩되는 식입니다. 궁극적으로 dst 텍스처는 앞에서 뒤로 순서로 합성된 모든 레이어를 포함하며, 이는 배경에 적용됩니다.
왜 dst 텍스처가 (0, 0, 0, 0)이 아니라 (0, 0, 0, 1)로 지워지는지 궁금할 수 있습니다. 레이어 0은 완전히 투명해야 하지 않을까요? 맞습니다, 첫 번째 레이어는 완전히 투명해야 하며 색상은 (0, 0, 0, 0)이어야 합니다. 그러나 앞에서 뒤로 블렌딩에서는 알파 채널을 A_{dst} 자체 대신 (1.0−A_{dst})를 저장하는 데 사용합니다. 따라서 여기서는 알파를 1.0으로 설정합니다.
const renderPassCleanupDesc = {
colorAttachments: [{
view: dstTexture.createView(),
clearValue: { r: 0, g: 0, b: 0, a: 1 },
loadOp: 'clear',
storeOp: 'store'
}]
}
let passEncoderCleanup = commandEncoder.beginRenderPass(renderPassCleanupDesc);
passEncoderCleanup.setViewport(0, 0, canvas.width, canvas.height, 0, 1);
passEncoderCleanup.end();
실제 렌더링을 위해 교대로 사용할 두 개의 깊이 맵을 정의합니다. 각 필링 단계에서 한 깊이 맵에서 깊이 값을 읽고 다른 맵에 씁니다. 동일한 깊이 맵에 동시에 읽고 쓸 수 없으므로 두 개의 깊이 맵을 교대로 사용합니다.
depthAttachment0 = {
view: depthTexture1.createView(),
depthClearValue: 1,
depthLoadOp: 'clear',
depthStoreOp: 'store'
};
depthAttachment1 = {
view: depthTexture0.createView(),
depthClearValue: 1,
depthLoadOp: 'clear',
depthStoreOp: 'store'
};
let colorAttachment0 = {
view: colorTextureForDebugging.createView(),
clearValue: { r: 0, g: 0, b: 0, a: 0 },
loadOp: 'clear',
storeOp: 'store'
};
let colorAttachment1 = {
view: colorTextureForDebugging.createView(),
clearValue: { r: 0, g: 0, b: 0, a: 0 },
loadOp: 'clear',
storeOp: 'store'
};
const renderPassDesc0 = {
colorAttachments: [colorAttachment0],
depthStencilAttachment: depthAttachment0
};
const renderPassDesc1 = {
colorAttachments: [colorAttachment1],
depthStencilAttachment: depthAttachment1
};
for (let p = 0; p < 6; ++p) {
let passEncoder0 = null;
if (p % 2 == 0) {
passEncoder0 = commandEncoder.beginRenderPass(renderPassDesc0);
}
else {
passEncoder0 = commandEncoder.beginRenderPass(renderPassDesc1);
}
passEncoder0.setViewport(0, 0, canvas.width, canvas.height, 0, 1);
teapot.encode(passEncoder0, pipeline, p);
plane.encode(passEncoder0, pipeline, p);
sphere.encode(passEncoder0, pipeline, p);
passEncoder0.end();
let passEncoder1 = commandEncoder.beginRenderPass(renderPassBlend);
passEncoder1.setViewport(0, 0, canvas.width, canvas.height, 0, 1);
blender.encode(passEncoder1);
passEncoder1.end();
}
처음에 깊이 맵을 모두 1로 초기화합니다. 1은 가능한 최대 깊이 값이므로, 첫 번째 필링 단계에서 가장 앞에 있는 레이어를 렌더링할 수 있습니다.
색상 첨부 파일의 경우, 앞에서 뒤로 렌더링을 위해 항상 (0, 0, 0, 0)으로 지웁니다.
필링 단계를 6번 반복하는 것을 주목하세요. 이 하드코딩된 값은 최대 6개의 레이어만 벗겨낼 수 있음을 의미합니다. 장면에 더 많은 레이어가 있으면 프로그램이 이를 처리할 수 없습니다. 이는 현재 구현의 한계이며, 지원되는 최대 레이어 수를 미리 결정해야 합니다.
객체를 렌더링한 후, 블렌더를 호출하여 새로 렌더링된 레이어를 기존 레이어에 합성합니다. 블렌더에 대해서는 나중에 자세히 설명하겠습니다.
struct VertexOutput {
@builtin(position) clip_position: vec4,
@location(0) tex_coords: vec2
};
@vertex
fn vs_main(
@location(0) inPos: vec4
) -> VertexOutput {
var out: VertexOutput;
out.clip_position = vec4(inPos.xy, 0.0, 1.0);
out.tex_coords = inPos.zw;
return out;
}
// Fragment shader
@group(0) @binding(0)
var t_src: texture_2d;
@group(0) @binding(1)
var s: sampler;
@fragment
fn fs_main(in: VertexOutput) -> @location(0) vec4 {
var color:vec4 = textureSample(t_src, s, in.tex_coords);
return color;
}
셰이더는 간단합니다. 텍스처(렌더링된 레이어)를 로드하고 프레임버퍼에 적용합니다. 중요한 부분은 파이프라인의 알파 블렌딩 설정입니다:
const colorState = {
format: 'bgra8unorm',
blend: {
color: {
operation: "add",
srcFactor: 'dst-alpha',
dstFactor: 'one',
},
alpha: {
operation: "add",
srcFactor: 'zero',
dstFactor: 'one-minus-src-alpha',
}
}
};
이는 이전에 설명된 것과 동일한 블렌딩 방정식을 사용하며, 원본 색상이 이미 미리 곱해져 있다고 가정합니다 (객체 렌더링을 위한 셰이더 참조).
const renderPassBlend = {
colorAttachments: [{
view: dstTexture.createView(),
clearValue: { r: 0, g: 0, b: 0, a: 0 },
loadOp: 'load',
storeOp: 'store'
}]
}
let passEncoder1 = commandEncoder.beginRenderPass(renderPassBlend);
passEncoder1.setViewport(0, 0, canvas.width, canvas.height, 0, 1);
blender.encode(passEncoder1);
passEncoder1.end();
위의 렌더 패스 디스크립터는 정리된 대상(dst) 텍스처로 시작합니다. dst 텍스처는 (0, 0, 0, 1)로 지워졌고, 그 이후로는 텍스처를 더 이상 지우지 않습니다. 텍스처는 이미 합성된 레이어를 포함하고 있으므로 각 블렌딩 작업에서 로드합니다.
struct VertexOutput {
@builtin(position) clip_position: vec4,
@location(0) tex_coords: vec2
};
@vertex
fn vs_main(
@location(0) inPos: vec4
) -> VertexOutput {
var out: VertexOutput;
out.clip_position = vec4(inPos.xy, 0.0, 1.0);
out.tex_coords = inPos.zw;
return out;
}
// Fragment shader
@group(0) @binding(0)
var t_composed: texture_2d;
@group(0) @binding(1 )
var s_composed: sampler;
@fragment
fn fs_main(in: VertexOutput) -> @location(0) vec4 {
return textureSample(t_composed, s_composed, in.tex_coords);
}
const colorState = {
format: 'bgra8unorm',
blend: {
alpha: {
operation: "add",
srcFactor: 'one',
dstFactor: 'one-minus-src-alpha',
},
color: {
operation: "add",
srcFactor: 'one',
dstFactor: 'one-minus-src-alpha',
}
}
};
let finalEncoder = commandEncoder.beginRenderPass(renderPassFinal);
final.encode(finalEncoder);
finalEncoder.end();
마지막으로, 최종 단계에서 합성된 레이어를 검은색 배경 위에 뒤에서 앞으로 블렌딩하여 렌더링합니다. 색상이 미리 곱해져 있으므로, C_{src} +(1−A_{src}) \times C_{dst} 공식을 사용합니다.
