4.0 프리픽스 합
이 장의 초점은 WebGPU를 통해 제공되는 새로운 기능인 컴퓨트 셰이더입니다. 컴퓨트 셰이더를 사용하면 GPU의 기능을 활용하여 일반적인 계산을 수행할 수 있습니다. 예를 들어, AI 추론은 웹에서 이러한 기능이 가능하게 할 수 있는 흥미로운 예시입니다.
첫 번째 튜토리얼에서는 수많은 병렬 알고리즘의 기본 구성 요소인 프리픽스 합(스캔이라고도 함) 계산을 다룰 것입니다. 이어서, 두 번째 튜토리얼에서는 정렬이라는 또 다른 중요한 알고리즘 연산에 프리픽스 합 기술을 활용할 것입니다. 마지막으로, 세 번째 튜토리얼에서는 시뮬레이션을 위한 컴퓨트 셰이더와 렌더링 셰이더의 통합을 통해 "반응-확산(reaction diffusion)"이라는 애니메이션 시연을 만드는 방법을 선보일 것입니다.
이 튜토리얼들을 통해 우리는 컴퓨트 셰이더의 다용도성과 실용성을 보여주고, WebGPU 영역에서 계산 및 그래픽 기능을 향상시키는 데 있어 그 중요성을 명확히 하는 것을 목표로 합니다.
정수 배열에 적용되는 프리픽스 합 알고리즘은 동일한 길이의 새 배열을 생성합니다. 이 새 배열의 각 요소는 원본 배열에서 해당 위치 앞에 있는 모든 요소의 합계를 나타냅니다. 예를 들어 배열 [1, 2, 3]을 고려하면 프리픽스 합은 [0, 1, 3]이 됩니다.
프리픽스 합에는 독점(exclusive)과 포괄(inclusive)의 두 가지 변형이 있습니다. 독점 프리픽스 합에서는 각 항목이 해당 위치 앞에 있는 모든 요소의 합계를 나타내며, 해당 요소 자체는 제외됩니다. 반면에 포괄 프리픽스 합은 합계에 현재 위치의 값을 포함합니다. 이 튜토리얼에서는 독점 프리픽스 합 알고리즘 구현에 초점을 맞출 것입니다.
CPU에서 for 루프를 사용하여 프리픽스 합을 구현하는 것은 간단합니다. 그러나 GPU에서 병렬 방식으로 효율성을 달성하는 것은 어려운 일입니다. 이러한 어려움은 프리픽스 합 연산의 본질적으로 순차적인 특성에서 비롯됩니다. 항목의 값을 계산하려면 모든 선행 항목을 검토해야 하며, 이는 본질적으로 순차적인 연산처럼 보입니다. GPU에서는 각 요소의 계산이 선행 요소에 명백히 의존하기 때문에 대규모 병렬 아키텍처를 이러한 연산에 활용하는 것이 즉각적으로 직관적이지 않습니다.
프리픽스 합 알고리즘의 복잡한 부분에 들어가기 전에, 먼저 컴퓨트 셰이더 설정의 일반적인 구조를 이해하고 이를 렌더링 셰이더와 비교해 보겠습니다. 처음 셰이더 코드를 살펴보면 차이점이 크지 않아 보일 수 있지만, 분명한 미묘한 차이점이 존재합니다.
@binding(0) @group(0) var input :array;
@binding(1) @group(0) var output :array;
@binding(2) @group(0) var sums: array;
const n:u32 = 512;
var temp: array; //workgroup array must have a fixed size;
const bank_size:u32 = 32;
@compute @workgroup_size(256)
fn main(@builtin(global_invocation_id) GlobalInvocationID : vec3,
@builtin(local_invocation_id) LocalInvocationID: vec3,
@builtin(workgroup_id) WorkgroupID: vec3) {
var thid:u32 = LocalInvocationID.x;
var globalThid:u32 = GlobalInvocationID.x;
}
첫째, 우리는 렌더링 작업에서는 덜 탐구되었던 측면인 입력 데이터에 스토리지 버퍼를 주로 사용하게 됩니다. 유니폼 대신 스토리지 버퍼를 활용하면 상당한 이점을 제공합니다. 특히, 유니폼은 대용량 데이터를 처리하는 데 적합하지 않은 반면, 스토리지 버퍼는 이 점에서 탁월합니다. 유니폼 버퍼 바인딩은 최대 64KB(maxUniformBufferBindingSize) 크기로 제한되는 반면, WebGPU의 스토리지 버퍼 바인딩은 최소 128MB(maxStorageBufferBindingSize)의 용량을 자랑합니다. 또한 스토리지 버퍼는 쓰기 가능하여 결과 데이터를 다시 읽거나 후속 단계를 위해 데이터를 준비하는 데 특히 유용합니다.
또한, 우리의 메인 함수는 이제 @compute @workgroup_size(256) 데코레이션을 가집니다. 이는 컴퓨트 셰이더에만 있는 "워크그룹" 개념을 도입합니다. 컴퓨트 셰이더를 호출할 때, 호출할 그룹의 수를 지정하는 것은 필수입니다. 각 그룹은 여러 스레드로 구성되며, 정확한 스레드 수는 @workgroup_size 데코레이션에 의해 정의됩니다. 예를 들어, 여기서는 허용되는 최대 값(maxComputeInvocationsPerWorkgroup)인 그룹당 256개의 스레드를 지정하는 예시가 나와 있습니다.
“스레드”라는 용어를 공유하지만, GPU 스레드는 CPU 스레드와 다릅니다. CPU 프로그램에서는 여러 스레드가 동시에 다른 프로그램을 실행할 수 있습니다. 그러나 동일한 워크그룹 내의 GPU 스레드에서는 균일성이 필수적입니다. 즉, 동일한 프로그램을 실행해야 합니다.
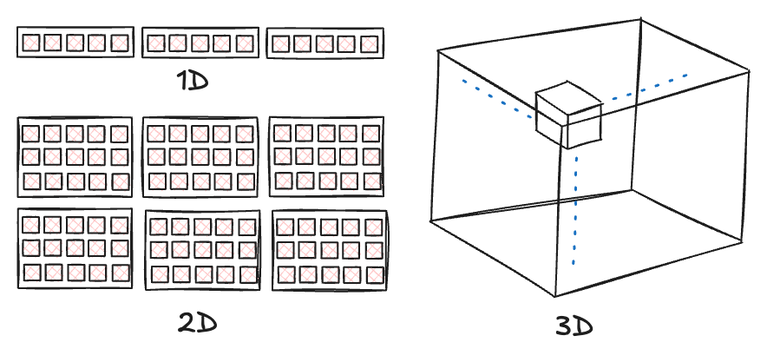
스레드 수와 그룹 크기는 편의를 위해 최대 3차원으로 지정할 수 있습니다. 차원 선택은 문제의 본질에 따라 달라집니다. 목표는 큰 문제를 작은 조각으로 나누어 각 스레드가 다른 스레드와 간섭 없이 처리하도록 하는 것입니다. 예를 들어, 이미지 처리 시나리오에서는 각 픽셀에 대한 병렬 계산을 허용하는 2D 워크그룹과 스레드를 사용하는 것이 가장 직관적일 수 있습니다. 반대로, 프리픽스 합과 같은 작업의 경우 1D 배열에서 작동하므로 1D 스레드와 그룹을 활용하는 것이 최적의 선택임을 입증합니다.
그룹과 스레드의 차원성은 순전히 편의를 위한 목적을 가집니다. 선택된 차원성과 관계없이 그들의 근본적인 성격은 동일합니다. 본질적으로 컴퓨트 셰이더 호출은 두 계층 구조를 따릅니다. 최상위 계층은 그룹으로 구성되고, 각 그룹 내에는 개별 스레드가 존재합니다. 그룹 수는 런타임에 지정할 수 있지만, 각 그룹 내의 스레드 수는 정적(셰이더에 하드코딩)으로 유지됩니다.
컴퓨트 셰이더와 렌더링 셰이더의 주요 차이점은 컴퓨트 셰이더에는 입력에 대한 일반적인 정점 속성이 없다는 점입니다. 그러나 컴퓨트 셰이더는 스레드와 그룹을 식별하는 정보를 제공하는 특정 내장 함수를 도입합니다. 컴퓨트 셰이더는 주로 스토리지 버퍼를 통해 데이터를 입력받지만, 이러한 내장 ID는 해당 버퍼 내의 데이터에 접근하기 위한 인덱스 역할을 효과적으로 수행할 수 있습니다.
메인 함수의 내장 매개변수를 통해 컴퓨트 셰이더에 제공되는 스레드 ID 및 그룹 ID 개념을 살펴보겠습니다. 워크그룹 내의 각 스레드는 ID를 가집니다. 예를 들어, 각 그룹에 256개의 스레드가 할당되면 스레드 ID는 0부터 255까지입니다. 중요한 것은 여러 그룹을 실행해도 각 그룹 내의 스레드 ID 범위는 변경되지 않고, 0부터 255까지 유지된다는 점입니다. 이를 local_invocation_id라고 합니다. 또한, 세 그룹을 실행하는 시나리오에서는 0부터 2까지의 workgroup_id가 있습니다. 실행된 모든 워크그룹의 모든 스레드 중에서 스레드의 ID, 즉 전역 ID를 얻으려면 간단한 공식이 적용됩니다: workgroup_id * workgroup_size + local_invocation_id. 편의를 위해 WebGPU는 global_invocation_id라는 또 다른 내장 매개변수를 제공합니다.
그룹과 스레드 모두 다양한 차원 구성으로 조직될 수 있다는 점을 주목하는 것이 중요합니다. 결과적으로 단일 숫자가 ID 역할을 하는 대신, ID는 x, y, z 구성 요소를 가진 벡터로 나타날 수 있습니다. 그렇다면 2D 또는 3D global_invocation_id는 어떻게 계산할까요? 우리는 단순히 그룹과 스레드를 행렬로 봅니다. 각 그룹은 이 행렬 내의 항목을 나타내고, 해당 스레드는 그 그룹 내의 또 다른 행렬을 형성합니다.
워크그룹 개념을 소개했으니, 이제 새로운 할당 유형인 var을 살펴보겠습니다. 이 할당 유형의 버퍼는 동일한 워크그룹 내의 스레드만 독점적으로 접근할 수 있습니다. 워크그룹 할당을 활용하면 스토리지 버퍼에 비해 셰이더 프로그램 성능을 크게 향상시킬 수 있습니다. 그러나 고려해야 할 측면이 있습니다. 바로 뱅크 충돌(bank conflict)인데, 이는 최적화 전략을 통해 관리할 수 있는 문제입니다. 이에 대해서는 나중에 자세히 논의할 것입니다.
주목할 핵심 사항은 워크그룹 버퍼가 특정 그룹에만 한정되어 각 그룹 외부의 스레드에 대한 접근을 제한한다는 것입니다. 일반적으로 워크그룹 버퍼는 빠르고 지역적인 스토리지 솔루션으로, 주로 임시 데이터 저장을 위해 설계되었습니다.
let pass1UniformBindGroupLayout = device.createBindGroupLayout({
entries: [
{
binding: 0,
visibility: GPUShaderStage.COMPUTE,
buffer: { type: 'read-only-storage' }
},
{
binding: 1,
visibility: GPUShaderStage.COMPUTE,
buffer: { type: "storage" }
},
{
binding: 2,
visibility: GPUShaderStage.COMPUTE,
buffer: { type: "storage" }
}
]
});
JavaScript에서 컴퓨트 셰이더를 설정하는 방법을 살펴보겠습니다. 첫 번째 단계는 바인드 그룹 레이아웃을 구성하는 것입니다. 컴퓨트 셰이더에서 스토리지 버퍼를 자주 사용한다는 점을 고려할 때, 스토리지 버퍼용 바인드 그룹 레이아웃을 설정할 때는 버퍼 유형을 스토리지 유형—특히 읽기/쓰기 작업에는 'storage', 읽기 전용 접근에는 'read-only-storage'—으로 지정하는 것이 중요합니다. 또한, 버퍼 가시성(visibility)은 이제 GPUShaderStage.COMPUTE로 변경됩니다.
스토리지 버퍼를 사용하면 특정 데이터 유형, 특히 'array
예를 들어 'array
메모리 정렬 요구 사항은 호스트 측 메모리 준비에만 적용된다는 점에 유의하는 것이 중요합니다. 셰이더 코드 내에서는 이 추가 패딩이 프로그래머에게 투명하게 유지되어, 정렬을 위해 도입된 패딩에도 불구하고 'array
const pass1PipelineLayoutDesc = { bindGroupLayouts: [pass1UniformBindGroupLayout] };
const pass1Layout = device.createPipelineLayout(pass1PipelineLayoutDesc);
const pass1ComputePipeline = device.createComputePipeline({
layout: pass1Layout,
compute: {
module: pass1ShaderModule,
entryPoint: 'main',
},
});
const passEncoder = commandEncoder.beginComputePass(
computePassDescriptor
);
passEncoder.setPipeline(pass1ComputePipeline);
passEncoder.setBindGroup(0, pass1UniformBindGroup);
passEncoder.dispatchWorkgroups(chunkCount);
passEncoder.end();
commandEncoder.copyBufferToBuffer(outputArrayBuffer, 0,
readOutputArrayBuffer, 0, arraySize * 4);
commandEncoder.copyBufferToBuffer(outputSumArrayBuffer, 0,
readSumArrayBuffer, 0, sumSize * 4);
device.queue.submit([commandEncoder.finish()]);
await device.queue.onSubmittedWorkDone();
await readOutputArrayBuffer.mapAsync(GPUMapMode.READ, 0, arraySize * 4);
const d = new Float32Array(readOutputArrayBuffer.getMappedRange());
이어서 컴퓨트 파이프라인을 구성하는 것은 이전 절차와 유사합니다. 주목할 만한 차이점은 device.createComputePipeline을 호출하고 입력 내에 컴퓨트 항목을 지정한다는 점입니다. 이 항목은 컴퓨트 파이프라인의 진입점과 관련 셰이더 모듈을 정의합니다.
마지막 단계는 컴퓨트 셰이더를 호출하는 것입니다. 먼저 commandEncoder.beginComputePass를 호출하여 컴퓨트 패스를 시작합니다. 컴퓨트 패스가 시작되면 이전과 마찬가지로 파이프라인과 바인드 그룹을 설정합니다. 그러나 draw 또는 drawIndexed와 같은 함수를 사용하는 대신 dispatchWorkgroups를 사용하여 원하는 그룹 수를 지정합니다. 예를 들어, dispatchWorkgroups(2)는 2개의 그룹을 실행합니다. 각 그룹에는 여러 스레드가 포함된다는 점을 기억하는 것이 중요합니다. 예를 들어, 256개의 스레드로 그룹을 구성하고 2개의 그룹을 실행하면 총 512개의 스레드가 배포됩니다.
그룹은 컴퓨트 셰이더를 실행하기 위한 최소 단위입니다. 하지만 필요한 스레드 수가 256의 배수가 아닌 경우는 어떨까요? 예를 들어, 600개의 스레드가 필요한 경우에도 2개의 그룹을 실행해야 하므로 추가 스레드가 발생합니다. 컴퓨트 셰이더에서는 global_invocation_id를 검사하여 이러한 잉여 스레드를 식별하고, 아무 작업도 수행하지 않도록('doing nothing') 할당하여 효과적으로 관리하는 것이 중요합니다.
컴퓨트 셰이더를 포함하는 프로그램을 구성하는 방법을 논의했으니, 이제 프리픽스 합 알고리즘을 살펴보겠습니다. 단순한 프리픽스 합 구현을 작성하는 것은 어렵지 않습니다. 각 스레드에 자신의 global_invocation_id까지의 모든 요소의 합을 계산하는 작업을 할당하는 것은 간단해 보입니다. 그러나 이 접근 방식은 중복 계산으로 이어져 효율성을 저해합니다.
최적의 병렬 알고리즘은 '작업 효율성'을 추구하며, 직렬화된 버전과 비교하여 불필요한 작업을 수행하지 않도록 보장합니다. 그러나 각 스레드가 이전 스레드에 의해 계산된 합계를 포함하는 작업을 할당받는다면, 이는 본질적으로 모든 스레드가 선행 스레드의 계산이 완료될 때까지 기다려야 함을 의미합니다. 이는 전체 프로세스를 순차화하여 우리가 활용하고자 하는 병렬 처리의 이점을 상쇄시킵니다.
이제 작업 효율적인 병렬 프리픽스 합에 대해 자세히 알아보겠습니다. 트리 구조를 사용하여 개념을 설명하는 것부터 시작하겠습니다. 제가 이것을 '설명'이라고 부르는 이유는 실제 코드에서는 명시적으로 트리 데이터 구조를 생성하지 않기 때문입니다. 포인터와 관련된 복잡한 데이터 구조를 셰이더 코드 내에서 구성하는 것은 어렵습니다. 대신, 이 알고리즘은 배열만을 사용하여 이 문제를 영리하게 회피합니다. 그럼에도 불구하고, 기본 개념을 이해하기 위해서는 트리를 상상하는 것이 도움이 됩니다.
직렬화된 알고리즘을 병렬 알고리즘으로 변환하는 기본 원리는 문제를 더 작은 세그먼트로 나누는 것을 포함합니다. 그런 다음 각 스레드는 이 세그먼트 중 하나를 처리하고, 결과를 취합하여 더 작은 크기의 문제를 형성합니다. 이 과정은 최종 전역 결과에 도달할 때까지 반복됩니다. 대안으로, 또 다른 접근 방식은 작은 문제에서 시작하여 더 많은 결과를 생성하여 더 큰 독립적인 문제 집합을 만드는 것입니다. 그런 다음 병렬 스레드가 이를 해결하도록 할당되어 훨씬 더 큰 독립적인 문제 집합을 생성합니다. 우리의 프리픽스 합 알고리즘은 이 두 가지 기술을 능숙하게 활용합니다.
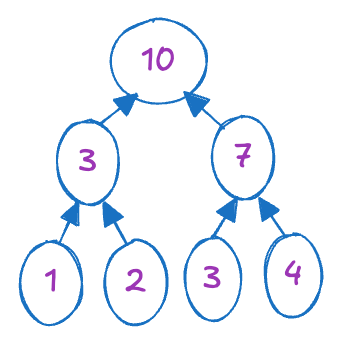
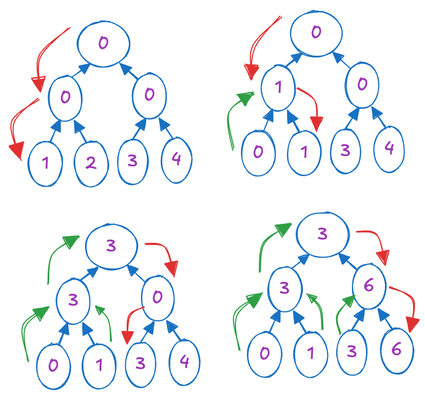
알고리즘의 초기 단계는 각 노드의 값이 서브트리의 합계를 나타내는 이진 트리를 구성하는 하향식(bottom-up) 처리 과정을 포함합니다. 이는 이전에 언급된 첫 번째 접근 방식과 일치하며, 입력 배열 크기 n을 n/2개의 두 요소 배열로 나누어 각 쌍의 합계를 독립적으로 계산하는 것을 목표로 합니다. 이 독립적인 계산은 n/2개의 새로운 값을 생성하여 문제 크기를 효과적으로 절반으로 줄입니다. 이 반복적인 과정은 입력 배열 내의 모든 요소의 합계를 나타내는 단일 합계에 도달할 때까지 계속됩니다.
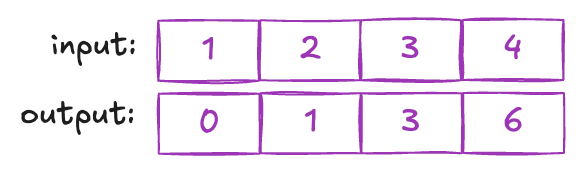
이 과정을 구체적인 예시로 설명하기 위해 입력 배열 [1,2,3,4]를 고려해 봅시다. 초기에는 이 배열을 두 개의 두 요소 배열인 [1,2]와 [3,4]로 나눕니다. 동시에 이들의 합계를 병렬로 계산하여 새로운 더 작은 배열 [3,7]을 얻습니다. 이 과정을 한 번 더 계속하면 최종 답변인 10에 도달합니다.
이진 트리를 구축했으니, 두 번째 단계는 루트에서 리프 노드로 이동하는 상향식(top-down) 접근 방식을 포함합니다. 루트 노드를 0으로 초기화합니다. 그런 다음 루트에서 리프 노드로 진행하면서 다음 작업을 계층적으로 적용합니다. 각 노드는 자신의 값과 왼쪽 자식의 값의 합계를 계산하고, 이 결과를 오른쪽 자식에게 할당합니다. 이어서 왼쪽 자식의 값은 현재 노드의 값으로 업데이트됩니다. 이 과정은 아래 그림을 사용하여 설명할 수 있습니다.
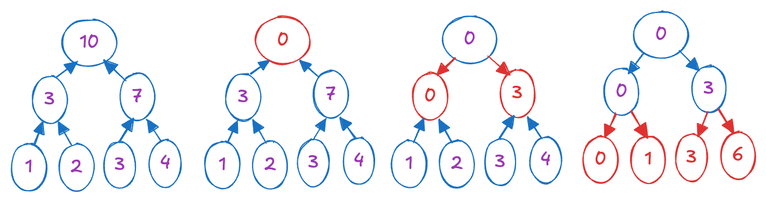
이 과정 뒤에 있는 직관을 이해하는 것은 어려울 수 있습니다. 개인적으로 저는 이것을 이진 트리의 깊이 우선 탐색(depth-first traversal)으로 인식하는데, 각 리프 노드를 방문하기 전에 해당 프리픽스 합을 계산하는 방식입니다. 위에서 설명한 과정은 주로 간단하고 효율적인 GPU 구현을 위한 최적화 역할을 합니다. 왜냐하면 실제 이진 트리를 구현하고 GPU에서 트리 탐색을 수행하는 것은 관련된 복잡성으로 인해 상당한 어려움을 초래하기 때문입니다.
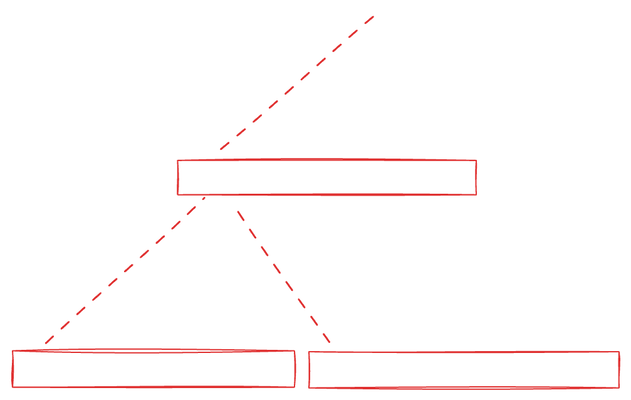
이 그림을 사용하여 깊이 우선 탐색 접근 방식을 설명하겠습니다:
초기 배열은 리프 노드를 나타냅니다. 우리는 깊이 우선 순서로 트리를 탐색하며, 현재 프리픽스 합을 추적하기 위한 임시 버퍼를 유지합니다. 리프 노드를 방문할 때, 해당 값을 현재 프리픽스 합으로 대체하고 노드의 원래 값을 프리픽스 합에 추가합니다. 이 과정은 모든 리프 노드를 방문할 때까지 계속됩니다.
이 방법은 GPU 구현과 유사합니다. 각 노드는 자신의 값과 왼쪽 자식의 값의 합계를 계산하고, 이 결과를 오른쪽 자식에게 할당하여 현재 프리픽스 합을 오른쪽 자식에게 효과적으로 전달합니다(위 접근 방식의 임시 버퍼 역할과 유사).
우리가 설명한 내용은 단일 그룹 내에서 실행될 수 있습니다. 단일 그룹의 최대 스레드 크기를 256으로, 그리고 스레드가 두 값의 합계를 계산할 수 있다는 점을 고려하면, 단일 그룹 내에서 512만큼 큰 배열을 처리할 수 있습니다. 그러나 입력 배열이 512요소를 초과할 경우, 이를 여러 개의 512 크기 청크로 분할하고 필요하다면 추가 엔트리를 0으로 패딩합니다. 그런 다음 여러 그룹이 할당되어 한 번의 패스에서 그룹별 프리픽스 합을 독립적으로 수행하고, 각 그룹의 총 합계를 중간 출력 배열에 작성합니다.
후속 패스에서는 첫 번째 단계에서 나온 합계의 수가 512를 초과하지 않을 것이라는 가정 하에 이 중간 출력에 대한 또 다른 프리픽스 합을 수행합니다. 이 가정은 최대 입력 배열 크기를 512^2으로 제한합니다. 더 큰 배열을 처리하려면 이 계층적 스키마를 여러 번 계속할 수 있습니다.
'패스'가 무엇을 의미하는지 명확히 하고 싶습니다. 우리 구현에서 패스는 일반적으로 dispatchWorkgroups 함수 호출을 통한 실행 배치(batch of execution)를 나타냅니다. 단일 패스에서 실행되는 그룹은 상호 의존성을 가져서는 안 됩니다.
두 개의 패스와 같은 여러 패스를 단일 패스로 처리할 수 없는 이유는 그룹의 동기화에 있습니다. 한 그룹이 도출한 결과를 두 번째 패스에서 사용하려면, 두 번째 패스의 그룹은 첫 번째 패스의 모든 그룹이 계산을 완료할 때까지 기다려야 합니다. 그러나 그룹 간에 서로를 동기화하는 메커니즘은 없으며, 동일한 그룹 내의 스레드만 이러한 기능을 가지고 있습니다. 이에 대해서는 잠시 후에 논의하겠습니다.
초기 과정에서 모든 그룹이 작업을 완료하도록 보장하려면 전용 패스 내에 포함해야 합니다. 이 패스가 완료되면 모든 그룹이 작업을 마쳤음을 확신할 수 있습니다. 이어서 두 번째 패스를 진행합니다.
두 번째 패스에서 그룹 프리픽스 합을 도출한 후, 세 번째 패스를 시작합니다. 각 그룹은 자신의 로컬 프리픽스 합과 그 전 그룹들의 프리픽스 합을 합산합니다.
이제 패스 1의 실제 코드를 살펴보겠습니다.
@binding(0) @group(0) var input :array;
@binding(1) @group(0) var output :array;
@binding(2) @group(0) var sums: array;
const n:u32 = 512;
var temp: array; //workgroup array must have a fixed size;
먼저, 입력 및 출력 배열을 설정합니다. 출력 배열은 첫 번째 패스 동안 이 그룹이 생성한 중간 출력을 저장하며, 'sums'는 모든 그룹이 도출한 합계를 담고 있습니다. 'n'은 이 그룹이 처리할 수 있는 최대 배열 크기를 나타냅니다.
또한, 계산에 사용되는 임시 버퍼로 'temp'를 도입합니다. 이는 워크그룹 할당으로 정의되어 있으며, 이는 다른 그룹에 의해 전역적으로 접근할 수 없이 각 그룹 내에 제한됨을 의미합니다. 워크그룹 할당을 활용하면 성능이 향상되므로, 가능한 한 이를 사용하여 성능을 극대화하는 것이 좋습니다."
이제 메인 함수로 넘어가면, 이 그룹에 특화된 ID를 받습니다:
@compute @workgroup_size(256)
fn main(@builtin(global_invocation_id) GlobalInvocationID : vec3,
@builtin(local_invocation_id) LocalInvocationID: vec3,
@builtin(workgroup_id) WorkgroupID: vec3) {
var thid:u32 = LocalInvocationID.x;
var globalThid:u32 = GlobalInvocationID.x;
if (thid < (n>>1)){
temp[bank_conflict_free_idx(2*thid)] = input[2*globalThid]; // load input into shared memory
temp[bank_conflict_free_idx(2*thid+1)] = input[2*globalThid+1];
}
}
'workgroup_size'는 256으로 설정되며, 이는 우리가 요청할 수 있는 최대 스레드 크기입니다. 다른 ID 유형은 고유한 목적을 가지며, 여기서는 'thid'가 0부터 255까지의 로컬 스레드 ID를 나타냅니다. 반면에 'globalThid'는 전역 ID를 의미합니다.
초기에는 'temp' 배열에 입력 데이터를 로드하는 것이 주요 작업입니다. 각 스레드는 2개의 연속적인 값을 로드합니다. 여기서 경계 조건을 확인할 필요가 없다고 생각할 수도 있지만('thid'는 (n >> 1) = 256보다 작음이 보장되므로), 셰이더에서 경계 검사를 구현하는 것이 좋은 습관입니다. 범위를 벗어난 인덱스에 접근하면 정의되지 않은 동작이 발생합니다. 일부 구현은 인덱스 접근 시 클램프(clamp)를 수행하여 마지막 항목이 일관되게 잘못되는 등 예상치 못한 동작을 초래할 수 있습니다. 이와 대조적으로 다른 구현은 범위를 벗어난 접근을 무효(void) 연산으로 처리할 수 있습니다. 이러한 불확실성이나 잘못된 값과 같은 잠재적 문제를 완화하기 위해 배열 접근 전에 경계 검사를 구현하는 것이 좋습니다.
다음으로, 하향식(bottom-up) 처리 과정을 진행합니다.
workgroupBarrier();
var offset:u32 = 1;
for (var d:u32 = n>>1; d > 0; d >>= 1)
{
if (thid < d)
{
var ai:u32 = offset*(2*thid+1)-1;
var bi:u32 = offset*(2*thid+2)-1;
temp[bank_conflict_free_idx(bi)] += temp[bank_conflict_free_idx(ai)];
}
offset *= 2;
workgroupBarrier();
}
이 과정에서는 log(512)번 루프를 돌면서 log(512) 레벨을 커버합니다. 각 레벨에서 단일 스레드가 두 항목의 합계를 제자리에서 실행하도록 할당됩니다. 결과 합계는 두 번째 항목에 기록됩니다. 'offset' 변수는 각 레벨에서 두 항목 사이의 간격을 나타냅니다. 처음에는 1로 설정되며, 각 계층에서 문제 크기를 절반으로 줄일 때 이 간격은 두 배가 됩니다.
이해해야 할 필수 함수는 workgroupBarrier()입니다. 이는 특정 지점에서 모든 스레드를 정지시키는 메모리 배리어를 호출합니다. 워크그룹 배리어라고 불리며, 임시 버퍼와 같은 워크그룹 할당에 대한 모든 이전 쓰기 작업이 읽기 작업 진행 전에 완료되었음을 보장합니다. 이 예방 조치는 읽기-쓰기 전 버그와 같은 문제를 완화합니다.
워크그룹 배리어와는 별개로 스토리지 배리어와 같은 다른 메모리 배리어가 있습니다. 스토리지 버퍼는 여러 그룹에서 접근할 수 있지만(워크그룹 버퍼와 달리), 스토리지 배리어는 이러한 그룹을 동기화하는 기능이 부족합니다. 그룹 동기화를 위해서는 패스에 의존합니다.
배리어를 개념화하려면 컴퓨터 과학 과정에서 자주 다루는 동기화 도구인 세마포어의 비유를 고려해 보세요. 세마포어가 GPU 메모리 배리어와 직접적으로 관련되지 않을 수 있지만, 배리어를 이해하기 위한 정신적 모델을 형성하는 데 도움이 됩니다.
세마포어는 제한된 자원을 관리하는 데 사용되며, 유한한 공간을 가진 주차장에 비유할 수 있습니다. 세마포어에는 사용 가능한 자원을 나타내는 카운터가 포함됩니다. 자원 사용 시, 세마포어 획득(acquire) 연산은 카운터를 감소시킵니다. 카운터가 0이 되어 자원 고갈을 의미할 때, 세마포어 획득을 시도하는 스레드는 다른 스레드가 세마포어 해제(release)를 실행하여 카운터를 증가시킬 때까지 멈춥니다.
유사하게, 배리어를 상상해 보면, 이 또한 0으로 초기화된 카운터를 중심으로 작동합니다. 스레드가 배리어 함수를 트리거하면 효과적으로 카운터를 증가시킵니다. 배리어 함수는 카운터가 총 스레드 수와 같아질 때만 스레드를 언블록합니다.
동기화 관련 작업을 다룰 때 명심해야 할 필수적인 측면은 중요한 균일성(uniformity) 요구 사항입니다. 사양에 명시된 바와 같이: '집단 연산(collective operation)은 GPU에서 동시에 실행되는 호출 간의 조정을 필요로 합니다.' 연산이 다른 호출에 걸쳐 정확하고 일관되게 실행되려면, 균일한 제어 흐름을 준수하면서 동시에 발생해야 합니다. 집단 연산은 배리어뿐만 아니라 텍스처 샘플링 함수도 포함합니다. 이들 또한 균일성 요구 사항을 가지며, 이는 후속 장에서 설명할 것입니다.
반대로, 비균일 제어 흐름에서의 집단 연산은 잘못된 동작으로 이어집니다. 이는 호출의 일부만이 연산을 실행하거나, 비균일 제어 흐름으로 인해 비동시적으로 실행될 때 발생합니다. 이러한 제어 흐름은 비균일 값에 의존하는 제어 흐름 문에서 발생합니다.
더 간단히 말해, 셰이더 코드가 받는 입력에 관계없이 집단 연산은 모든 스레드에 의해 균일하게 실행되어야 합니다. 예를 들어, 아래 코드 스니펫은 ID < 3인 스레드만 workgroupBarrier()를 트리거하고 다른 스레드는 그렇지 않기 때문에 유효하지 않으며 컴파일되지 않을 것입니다. 스레드 입력에 기반한 이러한 조건부 실행은 입력과 관계없이 모든 스레드가 연산을 실행해야 하므로 균일성을 위반합니다.
if (LocalInvocationID.x < 3) {
workgroupBarrier();
}내부 스레드 카운터를 가진 배리어에 대한 우리의 개념화는 비균일 실행이 왜 문제를 일으킬 수 있는지 명확히 합니다. 만약 스레드의 일부만이 배리어를 실행한다면, 내부 카운터는 총 스레드 수에 도달하지 못할 것이고, 이는 해당 함수를 호출하는 스레드들을 무한히 블록시키는 결과를 초래할 것입니다. 다행히도, 이것은 우리가 겪을 런타임 시나리오가 아닙니다. 컴파일러가 균일성 규칙을 위반하는 동기화 함수를 잡아낼 것입니다.
if (thid == 0)
{
sums[WorkgroupID.x] = temp[bank_conflict_free_idx(n - 1)];
temp[bank_conflict_free_idx(n - 1)] = 0;
} // clear the last element
workgroupBarrier();
다음 코드 세그먼트에는 합계를 'sum' 배열에 덤프하고, 'temp' 배열의 합계를 0으로 재설정하여 상향식(top-down) 처리 과정을 준비하는 내용이 포함됩니다. 이 연산은 전체 그룹에 대해 한 번만 필요하므로, ID가 0인 스레드에게 이 작업을 처리하도록 지정합니다.
마지막 단계는 상향식(top-down) 처리 과정과 최종 출력 작성입니다:
for (var d:u32 = 1; d < n; d *= 2) // traverse down tree & build scan
{
offset >>= 1;
if (thid < d)
{
var ai:u32 = offset*(2*thid+1)-1;
var bi:u32 = offset*(2*thid+2)-1;
var t:f32 = temp[bank_conflict_free_idx(ai)];
temp[bank_conflict_free_idx(ai)] = temp[bank_conflict_free_idx(bi)];
temp[bank_conflict_free_idx(bi)] += t;
}
workgroupBarrier();
}
if (thid < (n>>1)){
output[2*globalThid] = temp[bank_conflict_free_idx(2*thid)];
output[2*globalThid+1] = temp[bank_conflict_free_idx(2*thid+1)];
}
이것으로 첫 번째 패스가 완료됩니다. 이 단계가 끝나면, 우리는 모든 그룹의 프리픽스 합을 포함하는 출력 배열과 모든 그룹의 총합을 포함하는 합계 배열을 생성합니다.
두 번째 패스는 첫 번째 패스와 유사하게 총합을 출력하지 않고 합계들의 프리픽스 합만 계산하므로 더 간단합니다. 이 단계의 세부 사항은 생략되었습니다.
세 번째 패스는 각 그룹의 프리픽스 합에 모든 선행 그룹들의 합계를 더하는 간단한 과정입니다.
var thid:u32 = LocalInvocationID.x;
var globalThid:u32 = GlobalInvocationID.x;
if (thid < (n>>1)){
output[2*globalThid]= output[2*globalThid] + sums[WorkgroupID.x]; // load input into shared memory
output[2*globalThid+1] = output[2*globalThid+1] + sums[WorkgroupID.x];
}
이제 이 세 가지 패스의 호출을 관찰하기 위해 JavaScript 코드를 살펴보겠습니다. 첫 번째 및 세 번째 패스 모두에서 chunkCount와 동일한 수의 워크그룹을 시작합니다. chunkCount를 계산하려면 Math.ceil(arraySize / 512); 표현식을 활용하여 문제 크기를 수용할 수 있는 512의 최소 배수를 나타내도록 합니다. 반대로, 두 번째 패스는 단일 그룹으로만 실행되므로 최대 문제 크기가 512^2으로 제한됩니다.
passEncoder.setPipeline(pass1ComputePipeline);
passEncoder.setBindGroup(0, pass1UniformBindGroup);
passEncoder.dispatchWorkgroups(chunkCount);
passEncoder.end();
const pass2Encoder = commandEncoder.beginComputePass(computePassDescriptor);
pass2Encoder.setPipeline(pass2ComputePipeline);
pass2Encoder.setBindGroup(0, pass2UniformBindGroup);
pass2Encoder.dispatchWorkgroups(1);
pass2Encoder.end();
const pass3Encoder = commandEncoder.beginComputePass(computePassDescriptor);
pass3Encoder.setPipeline(pass3ComputePipeline);
pass3Encoder.setBindGroup(0, pass3UniformBindGroup);
pass3Encoder.dispatchWorkgroups(chunkCount);
pass3Encoder.end();
이 튜토리얼을 마치기 전에 GPU 코드의 벤치마킹에 대해 다루는 것이 중요합니다. GPU 코드는 별도의 장치에서 실행되므로, CPU 측면에서만 GPU 실행을 평가하면 정확한 결과를 얻지 못할 수 있습니다. 다행히 WebGPU는 성능 측정을 용이하게 하는 확장을 제공합니다.
이 확장 기능은 'timestamp-query'라고 불리며, Chrome의 실험적인 기능으로 --enable-dawn-features=allow_unsafe_apis 명령줄 옵션을 통해 특별히 활성화해야 합니다:
/Applications/Google\ Chrome.app/Contents/MacOS/Google\ Chrome --enable-dawn-features=allow_unsafe_apis어댑터에서 이 기능을 요청하려면 다음 JavaScript 스니펫을 따르세요:
const adapter = await navigator.gpu.requestAdapter();
const hasTimestampQuery = adapter.features.has('timestamp-query');
let device = await adapter.requestDevice({
requiredFeatures: hasTimestampQuery ? ["timestamp-query"] : [],
});더 나은 크로스 브라우저 호환성을 위해 벤치마크 관련 코드를 hasTimestampQuery 조건 내에 보호하는 것을 고려하세요. 이렇게 하면 브라우저 플래그가 제공되지 않거나 확장 기능이 지원되지 않는 경우에도 런타임 오류가 발생하지 않습니다.
'timestamp-query' 기능은 쿼리 세트라고 불리는 임시 저장소를 요청할 수 있도록 함으로써 작동합니다. 명령 버퍼 인코딩 중에 GPU에 현재 타임스탬프를 이 쿼리 세트에 기록하도록 지시할 수 있습니다. 타이밍 프로세스가 완료되면 쿼리 세트를 버퍼로 전송할 수 있습니다. 명령 버퍼가 완료된 후에는 버퍼를 호스트로 복사하여 타임스탬프에 접근할 수 있습니다. 타이밍이 전적으로 GPU에서 발생하므로 정확성이 보장됩니다.
const capacity = 3;//Max number of timestamps we can store
const querySet = hasTimestampQuery ? device.createQuerySet({
type: "timestamp",
count: capacity,
}) : null;
const queryBuffer = hasTimestampQuery ? device.createBuffer({
size: 8 * capacity,
usage: GPUBufferUsage.QUERY_RESOLVE
| GPUBufferUsage.STORAGE
| GPUBufferUsage.COPY_SRC
| GPUBufferUsage.COPY_DST,
}) : null;이 예에서는 'capacity'가 3으로 설정되어 버퍼에 최대 3개의 타임스탬프를 저장할 수 있습니다. 각 타임스탬프가 64비트 정수라는 점을 고려하여, 이러한 정수를 수용하기 위해 'queryBuffer' 크기는 'capacity'의 8배로 요청됩니다.
다음은 타이밍을 수행하는 방법입니다:
if (hasTimestampQuery) {
commandEncoder.writeTimestamp(querySet, 0);// Initial timestamp
}
... // perform the compute passes
if (hasTimestampQuery) {
commandEncoder.writeTimestamp(querySet, 1);// Second timestamp
commandEncoder.resolveQuerySet(
querySet,
0,// index of first query to resolve
capacity,//number of queries to resolve
queryBuffer,
0);// destination offset
}쿼리 세트에서 데이터를 추출하려면 resolveQuerySet 함수를 호출하여 이를 수행합니다. 명령 버퍼가 실행을 완료하면, 이전에 다른 버퍼 유형을 처리하는 데 사용했던 것과 유사한 과정에 따라 버퍼의 데이터를 검색합니다:
if (hasTimestampQuery) {
const gpuReadBuffer = device.createBuffer({ size: queryBuffer.size, usage: GPUBufferUsage.COPY_DST | GPUBufferUsage.MAP_READ });
const copyEncoder = device.createCommandEncoder();
copyEncoder.copyBufferToBuffer(queryBuffer, 0, gpuReadBuffer, 0, queryBuffer.size);
const copyCommands = copyEncoder.finish();
device.queue.submit([copyCommands]);
await gpuReadBuffer.mapAsync(GPUMapMode.READ);
let result = new BigInt64Array(gpuReadBuffer.getMappedRange());
console.log("run time: ", (result[1] - result[0]));
gpuReadBuffer.unmap();
gpuReadBuffer.destroy();
}타임스탬프가 int64 유형이므로, 버퍼를 BigInt64Array에 매핑하여 나노초 단위로 시간을 측정할 수 있다는 점에 유의하세요.
또 다른 중요한 고려 사항은 워크그룹 메모리 내의 뱅크 충돌(bank conflict)입니다. 다른 메모리 유형과 달리 워크그룹 메모리는 뱅크로 구성됩니다. 여러 스레드가 동시에 동일한 뱅크에 접근하려고 하면, 해당 실행이 직렬화됩니다. 즉, 한 스레드는 다른 스레드가 뱅크 접근을 마칠 때까지 기다려야 다음으로 진행할 수 있습니다. 이러한 현상을 뱅크 충돌이라고 하며, GPU 프로그래머가 최적화해야 할 중요한 측면입니다. 메모리 구성은 하드웨어에 따라 다르다는 점에 유의하는 것이 중요합니다.
여기에 제시된 정보는 NVIDIA의 문서에 기반을 두고 있으며 일반적으로 기본 구성으로 취급됩니다. 그러나 Apple 실리콘을 다룰 때는 메모리 구성에 대한 자세한 정보가 부족할 수 있습니다. 그러한 경우, 최적화 전략은 명시적인 문서에 의존하기보다는 벤치마크와 실험을 통해 도출되어야 합니다.
대부분의 하드웨어에서 연속적인 워크그룹 할당은 32비트마다 한 뱅크씩 진행됩니다. 예를 들어, array가 있다면, 할당은 4개의 뱅크에 걸쳐 이루어질 것입니다. 뱅크 충돌을 이해하고 해결하는 것은 GPU 프로그래밍의 효율성을 극대화하는 데 필수적입니다.