2.4 텍스트 렌더링
WebGPU와 같은 그래픽스 API에서 텍스트 렌더링의 복잡성은 종종 개발자들을 놀라게 합니다. 사용자 인터페이스부터 시각화 레이블, 2D 게임 콘텐츠에 이르기까지 다양한 3D 애플리케이션에서 텍스트 렌더링은 근본적으로 중요함에도 불구하고, 이러한 API에는 내장된 기능이 아닙니다. 대신, 효과적으로 구현하려면 상당한 노력이 필요합니다.
이 튜토리얼에서는 텍스트 렌더링의 기본 접근 방식을 소개하고, 완전한 기능을 갖춘 시스템에 대한 요구 사항과 다양한 방법론 간의 장단점을 제공합니다.
포괄적인 텍스트 렌더링 프로세스는 여러 복잡한 단계를 포함합니다. 텍스트를 렌더링할 때 시스템은 먼저 어떤 폰트 파일을 사용할지 결정해야 합니다. 개별 폰트 파일은 일반적으로 하나 또는 몇 개의 언어에 대한 문자 하위 집합만 포함하므로, 폴백 메커니즘이 필요합니다. 예를 들어, 영어와 중국어 문자를 혼합하여 렌더링할 때 시스템은 필요한 모든 글리프를 포함하기 위해 여러 폰트 파일을 사용해야 할 수 있습니다.
폰트 파일에는 글리프와 해당 측정값에 대한 데이터베이스가 포함되어 있습니다. 글리프가 항상 문자와 동일하지 않다는 점을 이해하는 것이 중요합니다. 글리프는 문자를 구성하는 데 사용되는 부분적인 요소일 수 있습니다. 예를 들어, 이모지 폰트 파일에서 선글라스를 낀 웃는 얼굴은 별도의 얼굴 및 선글라스 글리프로 표현될 수 있습니다. 이러한 구분은 폰트 렌더링의 복잡성을 크게 증가시킵니다.
텍스트 형태화(Text Shaping) 프로세스는 문자를 기본 형태(글리프)에서 문맥에 맞는 형태로 변환합니다. 여기에는 폰트 스타일, 합자, 문자 위치 지정 및 언어별 규칙과 같은 요소가 고려됩니다. 여러 폰트와 언어를 동시에 처리할 때 복잡성은 더욱 증가합니다.
폰트 래스터화는 또 다른 과제를 제시합니다. 대부분의 글리프는 선분 및 곡선과 같은 기하학적 데이터로 저장되므로, 크기 조정에 영향을 받지 않습니다. 그러나 다른 글리프, 특히 이모지는 비트맵 형식, 즉 작은 그림일 수 있습니다. 견고한 렌더링 함수는 이러한 다양한 형식을 원활하게 통합해야 합니다.
성능을 최적화하기 위해 텍스트 렌더링 시스템은 종종 문자 캐시를 구현합니다. 이 접근 방식은 이전에 본 문자에 대한 조회 테이블을 설정하여 반복적인 래스터화를 방지합니다. 이는 알파벳이 작은 언어에서는 더 효율적이지만, 문자가 많은 중국어와 같은 언어에서는 문제가 발생합니다. 또한, 시스템이 폰트 크기 조정을 처리해야 하는 경우, 정확한 해상도로 문자를 다시 렌더링하려면 캐시를 무효화해야 합니다.
더 긴 텍스트 구절의 경우, 특히 텍스트 컨테이너의 크기가 변경될 수 있을 때 텍스트 줄 바꿈 및 리플로우와 같은 고려 사항이 필요합니다.
이러한 복잡성을 고려할 때, 개발자들은 텍스트 렌더링을 처음부터 구현하는 경우가 거의 없습니다. 운영 체제는 종종 구현을 제공하지만, 좋은 크로스 플랫폼 솔루션을 찾는 것은 어려울 수 있습니다. 텍스트 형태화와 같은 특정 렌더링 단계에 사용할 수 있는 라이브러리가 있지만, 상당수는 C++ 환경용으로 설계되어 웹 개발을 위한 옵션을 제한합니다.
3D 그래픽스 컨텍스트에서는 종종 장단점이 필요합니다. 게임은 문자 캐싱을 단순화하기 위해 영어만 지원하도록 제한할 수 있으며, 터미널 또는 IDE 유형 애플리케이션은 텍스트 형태화를 간소화하기 위해 등폭 폰트를 선택할 수 있습니다.
플레이그라운드 실행 - 2_04_text이 튜토리얼에서는 텍스트 렌더링의 기본적인 구현을 살펴봅니다. 우리의 접근 방식은 2D 캔버스를 활용하여 텍스트를 그리고 텍스처 맵을 생성하며, 웹 브라우저의 기존 텍스트 기능을 사용하여 이전에 논의된 복잡성을 처리합니다. 이 방법은 프로세스를 단순화하지만, 특정 제약 사항이 따릅니다.
텍스트가 많은 애플리케이션의 경우, 이 접근 방식은 수많은 텍스처 맵 생성으로 인해 GPU 메모리를 빠르게 소모할 수 있습니다. 또한, 동적 텍스트 콘텐츠는 텍스트를 래스터화하고 텍스처 맵을 반복적으로 생성하는 데 시간이 많이 소요되어 성능 문제가 발생할 수 있습니다. 더욱이, 우리는 2D 컨텍스트에서 사용할 수 있는 폰트 스타일로 제한됩니다. 이러한 단점에도 불구하고, 이 방법은 레이블이나 간단한 사용자 인터페이스 렌더링과 같은 시각화 사용 사례에 매우 적합합니다.
이 접근 방식을 구현하는 코드를 살펴보겠습니다:
function printText(device, text) {
const width = 320;
const height = 240;
const canvas = new OffscreenCanvas(width, height);
const ctx = canvas.getContext("2d");
ctx.clearRect(0, 0, width, height);
ctx.globalAlpha = '0.5';
ctx.font = 'bold 32px Arial';
ctx.fillStyle = 'white';
const textMeasure = ctx.measureText(text); // TextM
console.log("texture measure", textMeasure);
console.log("width", Math.ceil(textMeasure.width))
ctx.fillText(text, 0, 28);
const textureDescriptor = {
size: { width: nearestPowerOf2(Math.ceil(textMeasure.width)), height: 32 },
format: 'rgba8unorm',
usage: GPUTextureUsage.TEXTURE_BINDING | GPUTextureUsage.COPY_DST | GPUTextureUsage.RENDER_ATTACHMENT
};
const texture = device.createTexture(textureDescriptor);
device.queue.copyExternalImageToTexture({ source: canvas, origin: { x: 0, y: 0 } }, { texture }, textureDescriptor.size);
return {texture, w: textMeasure.width / textureDescriptor.size.width, rw: textMeasure.width};
}
이 함수는 텍스트를 입력으로 받아, 오프스크린 캔버스를 사용하여 렌더링한 다음, 그 결과를 텍스처 맵에 로드합니다. 먼저 렌더링할 텍스트를 수용할 수 있을 만큼 충분히 큰 크기를 정의합니다. 이는 사용자 입력과 같이 동적으로 생성되는 텍스트의 경우 어려울 수 있으며, 이 방법의 또 다른 한계를 보여줍니다. 그러나 미리 정해진 정적 텍스트의 예제에서는 시행착오를 통해 적절한 크기를 선택할 수 있습니다.
이 크기를 기반으로 오프스크린 캔버스와 2D 컨텍스트를 생성합니다. 폰트와 fillStyle을 구성한 후, measureText 호출을 사용하여 텍스트를 측정하여 필요한 텍스처 크기를 결정합니다. RENDER_ATTACHMENT 사용은 copyExternalImageToTexture를 호출하는 데 필요하다는 점에 유의해야 합니다. 마지막으로 캔버스 내용을 텍스처 맵에 로드하고 반환합니다.
렌더링 프로세스는 텍스처 맵 튜토리얼과 매우 유사하지만, 한 가지 주요 차이점이 있습니다. 이제 투명 텍스처를 렌더링하고 있습니다. 올바른 렌더링을 위해 알파 블렌딩을 활성화해야 합니다.
const colorState = {
format: 'bgra8unorm',
blend: {
alpha: {
operation: "add",
srcFactor: 'one',
dstFactor: 'one-minus-src',
},
color: {
operation: "add",
srcFactor: 'one',
dstFactor: 'one-minus-src',
}
}
};
파이프라인을 정의하는 방법을 살펴보겠습니다. 여기서는 이미 배운 내용은 생략하고 차이점에 초점을 맞추겠습니다. 이번에는 파이프라인의 colorState를 정의할 때 알파 블렌딩을 지정해야 합니다.
알파 블렌딩에 대해 더 자세히 이야기할 필요가 있습니다. 프래그먼트 단계의 출력은 알파 채널이 있는 색상, 즉 투명할 수 있습니다. 우리는 이 투명 색상을 프레임버퍼에 어떻게 적용하거나 기존 프레임버퍼 내용과 어떻게 블렌딩할지 파이프라인을 구성하여 지정할 수 있습니다. 알파 블렌딩을 전혀 활성화하지 않으면 (기본 동작), 모든 것이 불투명 픽셀로 렌더링됩니다. 하지만 부분적으로 투명한 텍스처나 반투명 객체를 그리려면 알파 블렌딩을 활성화해야 합니다. 이는 텍스트 렌더링의 경우 특히 중요한데, 텍스트의 획만 불투명해야 하고, 다른 영역에서는 텍스트를 통해 배경을 볼 수 있도록 하기 위함입니다.
참고로, 유리 오브젝트와 같이 반투명 오브젝트를 렌더링하고 싶다면 알파 블렌딩만으로는 충분하지 않습니다. 투명도 지원에 대해서는 마지막 장에서 다룰 것입니다.
알파 블렌딩을 이해하려면 처음에는 혼란스러울 수 있는 두 가지 개념, 즉 블렌드 소스(blend source)와 블렌드 대상(blend destination)을 파악해야 합니다. 블렌드 소스는 프래그먼트 셰이더의 출력을 나타내고, 블렌드 대상은 프레임버퍼의 기존 내용입니다. 또한, 지정된 상수 값인 블렌드 상수(blend constant)가 있을 수 있습니다.
알파 채널과 색상 채널에 다른 블렌딩 동작을 할당할 수 있습니다. 구성을 위해 세 가지를 지정해야 합니다: 연산(operation), srcFactor, dstFactor. 최종 색상 또는 알파는 다음을 통해 얻을 수 있습니다:
\begin{aligned}
f_{sc} * C_s \bigodot f_{dc} * C_d &= C \\
f_{sa} * A_s \bigodot f_{da} * A_d &= A \\
\end{aligned}
여기서 f_{sc}와 f_{sa}는 색상 및 알파 채널에 대해 정의된 srcFactors이며, f_{dc}와 f_{da}는 dstFactors이고, \bigodot는 연산입니다.
실시간 컴퓨터 그래픽스에서 사용되는 몇 가지 일반적인 알파 블렌딩 공식을 그 적용 및 효과에 초점을 맞춰 살펴보겠습니다.
덧셈 블렌딩(Additive blending)은 빛에서 색상이 결합되는 방식을 모방하여, 두 색상이 합쳐질 때 더 밝은 결과를 냅니다. 이 과정은 모니터가 다양한 강도로 빨간색, 녹색, 파란색을 결합하여 색상을 생성하는 방식과 매우 유사합니다. 3D 렌더링에서 덧셈 블렌딩은 종종 파티클의 빛 방출이나 발광 효과를 생성하는 데 적용됩니다. 방정식 S + D는 이 블렌딩 모드를 나타내며, S는 소스 색상과 알파를, D는 대상(destination)을 나타냅니다.
곱셈 블렌딩(Multiplicative blending)은 빛이 흡수 매체 또는 필터와 상호 작용하는 방식을 시뮬레이션합니다. 이 연산은 색상을 어둡게 하는 경향이 있어 그림자와 같은 어두운 영역을 보존하는 데 유용합니다. 인쇄 산업에서는 유사한 원리를 사용하여 여러 번의 인쇄를 통해 더 어두운 색조를 얻습니다. 방정식 S * D는 곱셈 블렌딩을 포함합니다.
보간 블렌딩(Interpolative blending)은 이름 그대로 알파 값에 따라 두 색상 사이를 블렌딩합니다. 이 기술은 반투명 전경을 배경 위에 배치하거나 색조 유리(tinted glass)를 시뮬레이션할 때 매우 유용합니다. 소스 알파는 전경의 가시성을 제어하며, 다른 모드와 달리 객체 그리기 순서가 결과에 크게 영향을 미칩니다. 정확한 결과를 얻으려면 가장 먼 객체를 먼저 그린 다음 가까운 객체를 그리는 것이 중요합니다. 방정식 A_s * S + (1 - A_s) * D는 보간 블렌딩을 정의합니다.
이러한 예시는 블렌딩 효과의 표면에 불과합니다. 더 깊은 이해와 시각적 직관을 얻으려면 Photoshop과 같은 이미지 편집 소프트웨어로 실험해 보는 것을 고려해 보세요. 거기서 다양한 블렌딩 모드를 레이어에 적용할 수 있습니다.
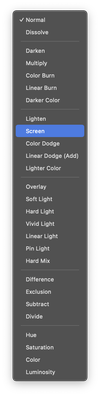
텍스트 렌더링 문제로 돌아가서, 배경 위에 텍스트가 포함된 텍스처 맵을 매끄럽게 블렌딩하는 데 중점을 둡니다. 이 시나리오는 보간 블렌딩과 완벽하게 일치합니다. 그러나 구현은 예상치 못한 결과를 보여줍니다.

결과 이미지에서 볼 수 있듯이, 문자 주위에 어두운 가장자리가 나타나 빨간색 배경에 순수한 흰색 텍스트라는 목표를 손상시킵니다. 이러한 어두운 가장자리는 알파 블렌딩과 보간을 함께 처리할 때 흔히 발생하는 아티팩트입니다.
우리 예시에서는 선형 보간을 사용하도록 텍스처 샘플러를 구성했습니다.
const sampler = device.createSampler({
addressModeU: 'repeat',
addressModeV: 'repeat',
magFilter: 'linear',
minFilter: 'linear',
mipmapFilter: 'linear',
});
이 구성은 앤티앨리어싱을 달성하는 데 필수적이지만, 의도치 않은 부작용을 초래합니다. 텍스트 텍스처를 생성할 때 ctx.clearRect(0, 0, width, height);를 사용하여 캔버스를 지웠다는 점을 기억하세요. 이 함수는 투명한 검은색 (0,0,0,0)으로 캔버스를 지웁니다. 반면, 텍스트를 그릴 때는 불투명한 흰색 (1,1,1,1)을 사용합니다.
이 문제는 GPU가 선형 보간을 사용하여 텍스처 샘플링을 하는 동안 발생합니다. 투명한 검은색 픽셀과 불투명한 흰색 픽셀 사이의 모든 샘플 위치는 회색 픽셀, 예를 들어 (0.5,0.5,0.5,0.5)를 초래할 수 있습니다. 이 효과는 텍스트 가장자리 근처에서 특히 두드러집니다. 우리가 알다시피, (0.5,0.5,0.5)는 회색을 나타내며, 텍스트 가장자리에서 더 어둡게 렌더링되는 이유를 설명합니다.
이러한 결과는 우리의 의도와 상충됩니다. 우리는 텍스트 색상 자체를 변경하지 않고 텍스트가 점차 배경으로 전환되기를 목표로 합니다. 문제는 알파 블렌딩을 통해 부드러운 가장자리를 얻으면서 텍스트의 선명한 흰색을 보존하는 데 있습니다.
이 문제는 실제로 흔하며 현재 시나리오를 넘어섭니다. 밉매핑과 반투명 텍스처를 결합할 때 덜 분명한 또 다른 상황이 발생하는데, 밉매핑 또한 이미지 레이어 간에 선형 보간을 사용하기 때문입니다.
이 문제에 대한 한 가지 해결책은 배경에 동일한 텍스트 색상을 사용하되, 알파 채널을 0으로 설정하는 것입니다. 이 접근 방식은 보간이 텍스트 색상을 변경하지 않도록 보장하여 블렌딩 프로세스 전반에 걸쳐 무결성을 유지합니다.
또 다른 더 정교한 해결책은 미리 곱한 알파 블렌딩(premultiplied alpha blending)을 구현하는 것입니다. 이 기술에서는 모든 색상 값이 블렌딩 전에 알파 값으로 곱해집니다. 예를 들어, 원래 색상이 (1.0,1.0,1.0,0.5)라면, 미리 곱한 버전은 (0.5,0.5,0.5,0.5)가 됩니다. 이 변환은 색상을 해석하는 방식을 변경하며, 특히 알파 값이 0인 색상에서 그렇습니다. 미리 곱한 (0,0,0,0) 색상은 더 이상 검은색으로 해석될 수 없습니다. 왜냐하면 알파 채널이 0일 때 모든 RGB 색상이 미리 곱한 형태로 (0,0,0)이 되기 때문입니다.
텍스트 렌더링의 아티팩트를 해결하기 위해, 텍스트 텍스처 맵을 미리 곱해진 것으로 처리할 수 있습니다. 이를 통해 배경색 (0,0,0,0)을 투명한 검은색이 아닌 투명한 흰색으로 해석할 수 있습니다. 그러나 이 접근 방식은 다른 블렌딩 공식을 필요로 합니다. 전경 색상이 미리 곱해졌으므로, 블렌딩 중에 알파 채널로 곱할 필요가 없습니다. 대신, 소스 계수(srcFactor)에 1 값을 사용합니다.
C_s + (1-A_s) * C_d = C
이제 개선된 블렌딩 접근 방식의 결과를 살펴보겠습니다:
어두운 가장자리 아티팩트에 대한 심층적인 수학적 분석을 제공하는 온라인 자료는 많지 않습니다. 저는 이 글이 매우 유용하다고 생각하며, 이 글을 읽어보는 것을 강력히 추천합니다.